Выполнение выражений
Структура и парсинг выражений
Выражения
Выражение, в самом общем смысле, — символьная запись действия, которое должно быть выполнено. Термин выражение может несколько сбивать с толку, так как в R есть выражения как запись кода (инструкция для интерпретатора), а есть отдельный тип объектов, expression, который также может быть переведен как “выражение”. Подробнее про тип expression здесь. В английском языке первому значению также может соответствовать ещё и термин statement.
Следует различать выражение и результат его выполнения. Так, в примере ниже x <- 5 и print(x ^ 2) — это выражения, а 25 — результат выполнения этих двух выражений:
x <- 5
print(x ^ 2)## [1] 25В R выражения представлены в виде четырёх форм:
- Имена (
names). При создании объекта, например,x <- 5происходит связывание значения5и имениx. Соответственно, далее можно обращаться к объекту со значением5по имениx, поэтому имена могут быть интерпретированы как выполняемые выражения. Например, если сделатьprint(x), то на печать будет выведен результат выполнения обращения к объекту по его имени:
print(x)## [1] 5- Константы. В R все единичные значения являются векторами длиной 1, соответственно, константы — это векторы единичной длины, которые не имеют имени. При выполнении выражения-константы возвращают себя же (
print()выводит на печать результат выполнения выражения):
print('this is constant value')## [1] "this is constant value"- Вызовы функций (
call). Этот форма выражения отражает процедуру вызова функции — её название и аргументы. Объекты типаcallможно создать с помощью одноименной функцииcall(), а также при парсинге R-скриптов. При использованииcall()конструируется выражение вызова функции, для выполнения этого выражения необходимо использоватьeval().
# создаём выражение округления значения
e_call <- call('round', 10.5)
# выражение не выполняется, есть только запись
print(e_call)## round(10.5)
# выполняем выражение
eval(e_call)## [1] 10Также результат выполнения многих функций может содержать отдельным элементом запись вызова функции. Это можно увидеть на примере результата функции lm():
# создаём lm-модель
x <- rnorm(100)
y <- 5 * x
lm_fit <- lm(y ~ x)
# смотрим вызов в подсписках
lm_fit$call## lm(formula = y ~ x)- Списки аргументов функций (
pairlists).pairlists— старая форма списков, унаследованная от S. В R эта форма встречается только в аргументах функций, во всех остальных местах замещены обычными списками,lists. Списки аргументов,pairlists, имеют видимя_аргумента = значение.
Захват выражений: quote() и substitute()
В R, особенно в современных пакетах, встречается достаточно много ситуаций, когда используется конструирование выражений или их отложенное выполнение (NSE, в частности). Такое поведение возможно благодаря инструментам захвата выражений, когда текст выражения рассматривается как отдельный объект, с которым можно производить какие-то манипуляции. Захваченные выражения имеют свой собственный тип language (см. базовые типы).
Для захвата выражения можно использовать несколько близких функций — quote(), bquote() и substitute(). Первая, quote() очень простая, фактически позволяет переданное в аргумент выражение выделить в отдельный объект.
## hp > 250Функция bquote() немного дополняет quote() и позволяет в выражении использовать другие объекты, а также указывать окружение:
## hp > 250Чаще всего для захвата выражений используется функция подстановки substitute(). В зависимости от того, в каком окружении она вызывается, может быть разный результат. Так, при вызове в глобальном окружении результат substitute() идентичен quote():
x_sbst <- substitute(hp > 250)
identical(x_q, x_sbst)## [1] TRUEОбычно substitute() используется в различных функциях, например, для создания названий переменных или осей в функциях data.frame() или plot(). При вызове в функции substitute() возвращает результат парсинга переданного выражения с подстановкой всех связанных переменных. Проще всего это увидеть вот в такой функции:
my_f <- function(x_arg) {
mult <- 5
list(
quote = quote(x_arg * mult),
substitute = substitute(x_arg * mult),
origin = x_arg * mult)
}
new_x <- 100
str(my_f(x_arg = new_x))## List of 3
## $ quote : language x_arg * mult
## $ substitute: language new_x * 5
## $ origin : num 500Как мы видим, quote() возвращает ровно то, что было передано в аргументы, выражение x_arg * mult. Аналогично ожидаем результат x_arg * mult — переданное в аргумент x_arg умножается на константу mult. При этом функция substitute() возвращает результат парсинга заданного выражения и подстановки значений переменных, само же выражение не выполняется.
При желании можно выполнить результат substitute() и сравнить с простым вычислением:
my_f <- function(x_arg) {
mult <- 5
identical(
x_arg * mult,
eval(substitute(x_arg * mult))
)
}
new_x <- 100
my_f(x_arg = new_x)## [1] TRUEСтоит отметить, что R Language Definition предупреждает, что в некоторых случаях поведение substitute() сложно контролируется и лучше использовать quote().
Абстрактное синтаксическое дерево
Код на R, который пользователь пишет в любой IDE или командной строке, — это, так или иначе, символьная запись выражений. Для того чтобы выполнить выражения, интерпретатор должен сначала их распарсить, т. е. разобрать на иерархию взаимосвязей действий и объектов. Подобная иерархия называется абстрактным синтаксическим деревом (АСД, AST), хотя корректнее, пожалуй, было бы переводить этот термин как дерево абстрактного синтаксиса. В R визуализировать AST выражения можно с помощью функции ast() пакета pryr — подобное представление бывает полезно для иллюстрации логики действия некоторых сложных выражений или конструкций языка.
Например, вычисление среднего по выборке десяти случайных значений из ряда от 1 до 100. Значения, которые начинаются с “`”, — это имена (names) объектов.
## \- ()
## \- `mean
## \- ()
## \- `sample
## \- 100
## \- 10Такое дерево само по себе демонстрирует некоторые особенности языка R — узлами выступают скобки () (выражения вызова функции), а переменные и функции — листьями. Это достаточно важный нюанс, так как иллюстрирует унаследованную от Lisp концепцию кода как данных, когда элементы языка являются такими же объектами, как и, например, таблицы. Наиболее важно это для нестандартного выполнения выражений, о котором пойдёт речь ниже. Меж тем, родство с Lisp можно проследить и просто в представлении дерева: (mean (sample 100 10)).
Вот так в синтаксическом дереве выглядят почти все типы выражений, которые существуют в R, за исключением вызовов функций. С константами и именами всё прозрачно, а вот [] представляет интерес — это как раз pairlists:
pryr::ast(function(x = 3, y = x * 2) x + y)## \- ()
## \- `function
## \- []
## \ x = 3
## \ y =()
## \- `*
## \- `x
## \- 2
## \- ()
## \- `+
## \- `x
## \- `y
## \- <srcref>Более понятную, но чуть менее иллюстрирующую особенности языка визуализацию дерева выражения можно получить с помощью функции lobstr::ast()
## █─mean
## └─█─sample
## ├─100
## └─10Парсинг выражений из строк и файлов: parse()
В R различают три основные модели парсинга строковых записей выражений:
Read-eval-print loop (REPL) — работа в интерфейсе командной строки, когда вся работа построена в виде последовательности действий “ввод команды — выполнение — результат”. В этой модели выражение пользователь пишет в командной строке, это выражение парсится интерпретатором и выполняется. Результат выполнения пользователь видит сразу же в консоли.
Парсинг текстовых файлов (файлов скриптов) — чтение и выполнение файлов скриптов. Обычно для этого используется комбинация
eval(parse(file = 'script.R'))или её более привычная и усложнённая форма,source().Парсинг строковой записи выражения — превращение записи вида
'x <- 5'в объект с классомexpression(). Для этого также используется функцияparse(), только символьная (строковая) запись передаётся в аргументtext. Например,parse(text = 'x <- 5').
Если файл содержит несколько выражений, то функция parse() вернёт их в виде списка выражений аналогично с парсингом строкового представления:
## [1] 2
expr_parsed[[1]]## x <- 5В некоторых случаях (как правило, в NSE) необходимо выражение превратить в строковую запись. Для этого используется функция deparse():
## [1] "expression"## [1] "character"Выполнение захваченных выражений
Выражения, которые были захвачены с помощью функций quote() / substitute() или преобразованы из строки, можно выполнить с помощью функции eval():
# создаём объект с выражением
e_q <- quote(new_val <- 5)
# проверяем, что объекта нет в рабочем окружении
'new_val' %in% ls()## [1] FALSE## [1] 5Аналогично с результатом функции parse():
# создаём объект с выражением
e_p <- parse(text = 'new_val2 <- 19')
# проверяем, что объекта нет в рабочем окружении
'new_val2' %in% ls()## [1] FALSE## [1] 19Очень часто при использовании функции eval() используется дополнительный аргумент, задающий окружение. Это позволяет выражения, созданные в каком-то одном окружении, выполнять в другом. Как правило это используется при написании функций или при нестандартном выполнении выражений (NSE).
# создаём окружение и объект выражения в нём
my_env <- new.env()
my_env$exp_in_env <- quote(new_val_env <- 'expr from new eval')
# проверяем, что нет выражения в окружениях
'new_val_env' %in% ls(envir = .GlobalEnv)## [1] FALSE
'new_val_env' %in% ls(envir = my_env)## [1] FALSE
# выполняем выражение в глобальном окружении
eval(my_env$exp_in_env, envir = .GlobalEnv)
# смотрим результат
new_val_env## [1] "expr from new eval"Выполнение функций
Promises, обещания
Выполнение функций в R может показаться несколько необычным для тех, кто привык работать, например, с Python. Утрированным примером будет следующая конструкция:
my_fun <- function(x, y, z = x * 2) {
z ^ 2
}
my_fun(2 + 3, stop('stop message'))## [1] 100Тут можно увидеть сразу несколько характерных аспектов my_fun():
при объявлении функции указывается три аргумента, однако функция выполняется, даже если передано только два аргумента;
в аргумент
zпередаётся не какой-то объект из глобального окружения, но результат операции над аргументомx;вычисление аргумента
xпроисходит, однако выражениеstop('stop message'), которое должно останавливать выполнение функции, не выполняется.
Подобное поведение возможно за счёт того, что в R называется promises, обещания. Это достаточно неудачный термин, так как обещания в R при выполнении функций никаким образом не связаны с асинхронными или отложенными вычислениями, в контексте которых обычно и используется термин promises. В определённой мере это можно объяснить тем, что в R promises появились намного раньше, чем асинхронные вычисления, но, тем не менее, в настоящий момент это порождает путаницу.
Обещание в R — это выражение с собственным связанным окружением, которое создаётся из аргумента функции при её вызове, для каждого аргумента своё обещание. Как правило, этот процесс скрыт и пользователи R не имеют прямого доступа к обещаниям. Тем не менее, можно воспользоваться функцией promise_info() пакета pryr и посмотреть структуру обещания:
val <- 4
my_fun <- function(x)
str(pryr::promise_info(x))
my_fun(val + 3)## List of 4
## $ code : language val + 3
## $ env :<environment: R_GlobalEnv>
## $ evaled: logi FALSE
## $ value : NULLКак мы видим, обещание состоит из нескольких элементов:
code— текст переданного в аргументxвыражения (val + 3);env— указатель окружения, в котором вызывается функция (<environment: R_GlobalEnv>);evaled— метка, выполнено ли какое-нибудь действие с аргументомx(FALSE);value— результ действия с аргументом (NULL).
До тех пор, пока с аргументом нет никаких операций, аргумент присутствует только в виде выражения как “обещание” вызова связанного с ним значения. Как только происходит вызов аргумента, элементы обещания меняются — уже нет необходимости хранить маркер окружения, в котором выполняется выражение аргумента, появляется результат выполнения выражения и значение аргумента, метка evaled меняется на TRUE:
my_fun <- function(x) {
cat("До действия с аргументом:\n")
str(pryr::promise_info(x))
# Вычисление в функции
res <- x * 2
cat("\nПосле действия с аргументом:\n")
str(pryr::promise_info(x))
cat("\nРезультат функции:\n")
res
}
my_fun(val + 3)## До действия с аргументом:
## List of 4
## $ code : language val + 3
## $ env :<environment: R_GlobalEnv>
## $ evaled: logi FALSE
## $ value : NULL
##
## После действия с аргументом:
## List of 4
## $ code : language val + 3
## $ env : NULL
## $ evaled: logi TRUE
## $ value : num 7
##
## Результат функции:## [1] 14При вызове функции сначала для аргумента функции создаётся обещание. Потом, когда необходимо сделать какое-то действие с аргументом (вычисление res), выполняется выражение, переданное в качестве аргумента (code). То есть обещание выполняется, и аргумент получает значение, в нашем случае это val + 3 = 7. В качестве результата функция возвращает вычисленное на основе значения аргумента x значение res.
Подобную ситуацию, в которой объект вычисляется только в тот момент, когда он вызывается, называют ленивым выполнением выражений, lazy evaluations. Это одна из самых важных особенностей организации выполнения выражений в R. lazy evaluations имеют как свои преимущества, так и недостатки. Главным преимуществом, наверное, будет экономия ресурсов. К недостаткам же можно отнести усложнение логики и затруднение отладки и тестирования.
Если возвращаться к примеру, с которого мы начали рассмотрение обещаний, то при вызове функции my_func() происходит создание трёх обещаний, для каждого из аргументов x, y, и z:
my_fun <- function(x, y, z = x * 2) {
cat('Окружение функции: \n')
print(environment())
cat('Обещание аргумента x, до выполнения: \n')
str(pryr::promise_info(x))
cat('Обещание аргумента y, до выполнения: \n')
str(pryr::promise_info(y))
cat('Обещание аргумента z, до выполнения: \n')
str(pryr::promise_info(z))
res <- z ^ 2
cat('Обещание аргумента x, после выполнения: \n')
str(pryr::promise_info(x))
cat('Обещание аргумента z, после выполнения: \n')
str(pryr::promise_info(z))
cat('Результат функции: \n')
res
}
my_fun(2 + 3, stop('stop message'))## Окружение функции:
## <environment: 0x56094fab20e8>
## Обещание аргумента x, до выполнения:
## List of 4
## $ code : language 2 + 3
## $ env :<environment: R_GlobalEnv>
## $ evaled: logi FALSE
## $ value : NULL
## Обещание аргумента y, до выполнения:
## List of 4
## $ code : language stop("stop message")
## $ env :<environment: R_GlobalEnv>
## $ evaled: logi FALSE
## $ value : NULL
## Обещание аргумента z, до выполнения:
## List of 4
## $ code : language x * 2
## $ env :<environment: 0x56094fab20e8>
## $ evaled: logi FALSE
## $ value : NULL
## Обещание аргумента x, после выполнения:
## List of 4
## $ code : language 2 + 3
## $ env : NULL
## $ evaled: logi TRUE
## $ value : num 5
## Обещание аргумента z, после выполнения:
## List of 4
## $ code : language x * 2
## $ env : NULL
## $ evaled: logi TRUE
## $ value : num 10
## Результат функции:## [1] 100Тут важно отметить, что обещание аргумента z выполняется в рабочем окружении функции. То есть когда происходит выполнение выражения z ^ 2, сначала выполняется обещание аргумента x, так как z вычисляется из x. Соответственно, z получает значение, и вычисляется уже результат действия с z, объект res. При этом аргумент y нигде не используется и не вызывается, поэтому выражение stop('stop message') так и остаётся в виде обещания и не выполняется.
Рекурсии
В R можно использовать рекурсивное выполнение функций — когда в теле функции вызывается эта же функция. Традиционно рекурсии иллюстрируют рядом Фибоначчи, когда каждый последующий член ряда является суммой двух предыдущих или же вычислением факториала числа.
Рекурсивная функция вычисления факториала (в общем виде n! = n * (n - 1)!) выглядит следующим образом:
# объявляем функцию
factorial_rec <- function(x) {
if (x <= 1) {
return(1)
} else {
return(x * factorial_rec(x - 1))
}
}
# считаем 5!
factorial_rec(5)## [1] 120Рекурсии ограничены памятью на стеке и в какой-то мере количеством итераций, так как при увеличении вложенности растёт и объём занимаемой памяти. Это можно увидеть, если попробовать посчитать факториал, например, 1000:
factorial_rec(1000)## Error: C stack usage 7975892 is too close to the limit
## Execution haltedПереписать рекурсивную функцию с использованием хвостовой рекурсии (tail recursion) в R можно, однако базовый R не предполагает её оптимизацию:
factorial_rec_tail <- function(n, acc = 1) {
if (n <= 1) acc
else factorial_rec_tail(n - 1, acc * n)
}
factorial_rec_tail(1000)## Error: C stack usage 7972260 is too close to the limit
## Execution haltedПоэтому самый простой способ оптимизировать рекурсивную функцию — это переписать её в виде цикла (Inf для n = 1000 возникает из-за того, что это слишком большое для отображения число, принципиальных проблем для вычисления нет):
factorial_loop <- function(n) {
res <- 1
while (n > 1) {
res <- n * res
n <- n - 1
}
res
}
factorial_loop(5)## [1] 120
factorial_loop(1000)## [1] InfЗамыкания
Функции, как правило, возвращают какой-то объект. Обычно это вектор, таблица или список. Однако точно так же функции могут возвращать и функции (которые точно такой же объект в R, как и таблицы и списки). Единственное отличие — возвращенные функции “помнят” определённые элементы окружения, в котором они были созданы (подробнее см. Лексическая область видимости).
Например, создадим функцию, которая принимает один аргумент и возвращает самостоятельную функцию, принимающую другой аргумент на вход, в теле которой происходит сложение этих двух аргументов. Тогда при вызове первой функции (my_func()) будет создана ещё одна функция (здесь new_func()), которая “помнит” значение переданного аргумента x и складывает его с уже своим аргументом:
# объявим функцию
my_fun <- function(x) {
function(y)
x + y
}
# вызовем с аргументом x = 2 (создадим новую функцию)
new_fun <- my_fun(x = 2)
# проверим класс и тело функции new_func()
class(new_fun)## [1] "function"
body(new_fun)## x + y
# применим функцию new_func()
new_fun(3)## [1] 5Такая структура, когда функция возвращает функцию, называется замыканием. Структурно функции с замыканием ничем не отличаются от обычных функций и создаются аналогично. Ниже приведён более приближённый к практике пример, когда функция с замыканием используется как генератор функций, формирующих ggplot2-график с той или иной темой. Сначала создаётся функция-генератор, принимающая в качестве аргумента название цветовой схемы (темы) графика. Эта функция при выполнении возвращает замыкание, которое, в свою очередь, создаёт график по заданным ранее параметрам и с указанной темой.
# подключаем пакет
library(ggplot2)
# создаём функцию-генератор с замыканием
ggplot_generator <- function(my_theme_name) {
my_ggplot <- function(data = NULL, mapping = aes(), ..., environment = parent.frame()) {
ggplot(data = data, mapping = mapping, ..., environment = environment) +
my_theme_name()
}
return(my_ggplot)
}Так как в теле функции используется аргумент ... и указывается родительское окружение как рабочее, то в полученную функцию можно передавать дополнительные аргументы — датасет, оси и проч.
# генерируем функцию, создающую график в белой теме
gg_dark <- ggplot_generator(my_theme_name = theme_minimal)
# применяем полученную функцию
gg_dark(iris, aes(x = Sepal.Width, y = Sepal.Length, colour = Species)) +
geom_point()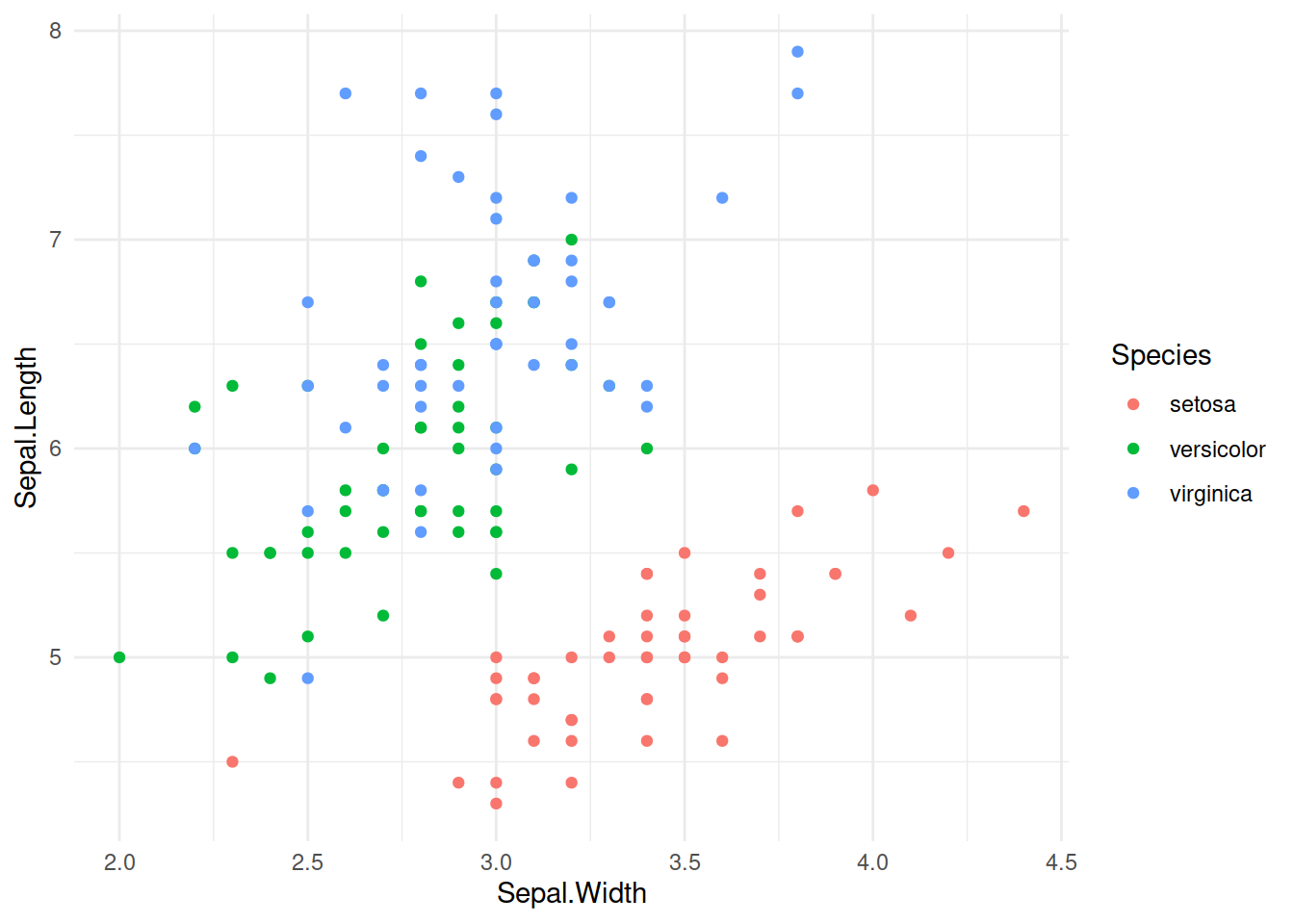
В целом применение замыканий — это “синтаксический сахар”, который призван либо упростить визуально конечный код, либо создать генератор функций для использования в незначительно различающихся ситуациях. Также замыкания используются для того, чтобы дополнить функцию, которую нельзя изменять (подобно декораторам в Python).
Нередко использование замыканий является лишь альтернативным путём решения уже предусмотренной разработчиками проблемы, как выше, с указанием тем. Несмотря на то, что функции с замыканиями ничем не отличаются от прочих префиксных функций, их использование может несколько ухудшить понятность кода, особенно для не очень искушённых аналитиков.
Частичное выполнение
Частичное выполнение функций — один из вариантов применения замыканий. При частичном выполнении функции часть аргументов используется, а часть может быть передана позже, в другом выражении. Это необходимо в тех ситуациях, когда хочется, например, сократить количество используемых аргументов. Пример частичного выполнения функции:
# создаём функцию, которая частично выполняет указанную функцию
partial <- function(f, ...) {
arglist <- list(...)
function(...) {
do.call(f, c(arglist, list(...)))
}
}
# создаём функцию, к которой хотим применить частичное выполнение
my_fun <- function(x, y, z) x + y + z
# создаём функцию, которая является частичным выполнением заданной
my_fun_pt <- partial(my_fun, x = 1, y = 2)
class(my_fun_pt)## [1] "function"
# применяем функцию, в которой часть аргументов уже выполнена
my_fun_pt(z = 3)## [1] 6Каррирование
Каррирование — преобразование функций нескольких аргументов в последовательность функций с одним аргументом, например, f(x, y) в f(x)(y). Каррирование использует механизм замыканий и, по сути, является расширением идеи частичного выполнения функции. Частичное выполнение предполагает возможность использования нескольких аргументов и создание функций с меньшим числом аргументов, в то время как каррирование — цепочка вызовов функций одного аргумента
# классическая функция
my_fun <- function(x, y, z) x + y + z
# каррируем функцию
my_fun_cr <- function(x) function(y) function(z) x + y + z
# применяем каррированную функцию
my_fun_cr(1)(2)(3)## [1] 6Если каррированную функцию выполнить лишь с частью аргументов, то в результате получится функция меньшего количества аргументов. То есть получится частичное выполнение. В примере ниже аргумент z не задан, в результате выполнения my_fun_cr() будет также функция. Здесь, что очевидно, важен порядок обработки аргументов в каррированной функции:
# выполняем только часть аргументов
my_fun_pt2 <- my_fun_cr(1)(2)
class(my_fun_pt2)## [1] "function"
# выполняем
my_fun_pt2(z = 3)## [1] 6Области видимости и окружения
Область видимости и окружение — очень близкие сущности, которые в ряде случаев легко спутать. Окружение — множество соотнесений (отображений, mappings) имён объектов и их значений (при этом окружение также может быть отдельным объектом в R, см. Окружения). Например, если в глобальном окружении выполнить выражение x <- 5, то x будет именем объекта, а 5 — значением. Функция pryr::where() возвращает название окружения, в котором создан объект с именем x и значением 5:
x <- 5
pryr::where('x')## <environment: R_GlobalEnv>Аналогично, если создать новое окружение и в нём создать объект с именем x и значением 5 (другими словами, объект new_x со значением 5):
## [1] "new_x"
pryr::where('new_x', env = myenv)## <environment: 0x56095336f210>Область видимости или локальное окружение — соотнесение названия объекта и какого-то конкретного объекта, вызываемого в определенной части кода (как правило, в функции). Пользователи R чаще всего могут столкнуться с созданием новых областей видимости при использовании анонимных функций, при создании функций, а также при использовании local(). Циклы, стоит отметить, не создают своб область видимости, и все операции над объектами в цикле происходят в родительском окружении цикла.
Лучше всего локальные окружения можно понять на следующем примере:
## [1] 5.477226Здесь мы видим x как объект в глобальном окружении и x как название аргумента функции myfunc(). Область видимости функции myfunc() — тело функции (выражения, заключенные в {}, вычисление суммы и квадратного корня). В этих выражениях x соотносится не с объектом x в глобальном окружении, а с переданным значением в аргумент x функции myfunc(). Объекты, созданные в локальной области видимости, недоступны в родительских окружениях, поэтому объект y отсутствует в глобальном окружении:
exists('x')## [1] TRUE
exists('y')## [1] TRUEЛексическая область видимости
Использование локальных объектов, т. е. имеющих ограниченную область видимости и существующих лишь внутри определенной функции, помогает избежать конфликта имён между двумя объектами с одинаковыми именами. В R используется лексическая область видимости (или лексическое связывание), когда имя объекта определяется и имеет значение внутри тела функции, а область видимость задаётся исключительно кодом. Собственно, поэтому и используется термин “лексическая”: по тексту кода можно проследить и восстановить, из какого окружения берётся тот или иной объект.
Для лексической области видимости характерно правило поиска объекта в родительских окружениях рекурсивно по восходящей. Например, в функции my_func() используется объект x, который создаётся и существует в родительском окружении:
x <- 9
myfunc <- function() sqrt(x)
myfunc()## [1] 3В момент выполнения myfunc() интерпретатор не находит объект x в локальной области видимости функции и обращается к родительскому окружению (в данном случае к глобальному). Можно усложнить пример и увеличить уровень вложенности:
x <- 5
y <- 2
myfunc1 <- function(x) {
cat('in myfunc1_l x = ', x, '\n')
x <- x + 5
myfunc2 <- function(y) {
cat('in myfunc2_l x = ', x, '\n')
y <- y + 2
x + y
}
res <- myfunc2(y)
cat('result of myfunc1 = ', res, '\n')
}
myfunc1(x)## in myfunc1_l x = 5
## in myfunc2_l x = 10
## result of myfunc1 = 14При этом важно обращать внимание, на то, где и как объявляется и вызывается функция, так как это прямо влияет на схему поиска объектов. Так, в примере выше функция myfunc2() объявляется внутри функции myfunc1(), соответственно, и поиск объекта x происходит сначала в родительском окружении для этой функции (локальное окружении функции myfunc1()). Если же функцию myfunc2() объявить отдельно в глобальном окружении, то объект x будет взят именно из глобального окружения, несмотря на то, что при выполнении функции myfunc1() он изменяется:
x <- 5
y <- 2
myfunc2 <- function(y) {
cat('x in myfunc2 = ', x, '\n')
y <- y + 2
x + y
}
myfunc1 <- function(x) {
x <- x + 5
cat('x in myfunc1 = ', x, '\n')
res <- myfunc2(y)
cat('resut of myfunc1 = ', res, '\n')
}
myfunc1(x)## x in myfunc1 = 10
## x in myfunc2 = 5
## resut of myfunc1 = 9Можно сделать ещё нагляднее, выведя на печать названия использованных окружений:
x <- 5
y <- 2
myfunc1 <- function(x) {
print(parent.frame())
print(environment())
x <- x + 5
cat('x in myfunc1 = ', x, '\n')
print(environment(myfunc2))
myfunc2(y)
}
myfunc2 <- function(y) {
print(parent.frame())
print(environment())
cat('x in myfunc2 = ', x, '\n')
y <- y + 2
x + y
}
myfunc1(x)## <environment: R_GlobalEnv>
## <environment: 0x560955b14978>
## x in myfunc1 = 10
## <environment: R_GlobalEnv>
## <environment: 0x560955b14978>
## <environment: 0x560955b1b778>
## x in myfunc2 = 5## [1] 9Динамическая область видимости
Наряду с лексическим связыванием в R иногда можно встретить и реализацию динамического связывания. При динамическом связывании учитывается окружение, в котором вызывается функция. В принципе, любой вызов функции в глобальном окружении одновременно является примером как лексического, так и динамического связывания имени объекта и собственно объекта. С некоторой натяжкой можно назвать примером динамического связывания ситуацию, когда произвольно указывается, из какого окружения берётся объект. Так, в примере ниже, если не указывается никакое окружение, используется лексическое связывание и объект y берётся из родительского (в данном случае глобального) окружения. В противном же случае объект y используется из созданного отдельного окружения new_env:
x <- 5
y <- 2
new_env <- new.env()
new_env$y <- 7
myfunc <- function(env = NULL) {
if (!is.null(env))
y <- get("y", envir = env)
x + y
}
myfunc()## [1] 7
myfunc(env = new_env)## [1] 12Окружение функции
В окружениях, в которых создаются или вызываются функции, достаточно легко можно запутаться. Контролировать, что это за окружения и как они взаимосвязаны, полезно для общего понимания процесса поиска объектов при выполнении кода и какова последовательность окружений, в которых интерпертатор ищет упомянутый в коде объект. В целом можно выделить четыре типа окружений функций, которые используются в R:
- Связанное окружение (
binding environment) — окружение, в котором есть объект с таким именем. Определить связанное окружение можно с помощью функцииfind():
# создаём функцию с именем f_genv в глобальном окружении
f_genv <- function() print('binding in global env')
f_genv()## [1] "binding in global env"
# смотрим, в каком окружении находится имя f_genv
find('f_genv')## [1] ".GlobalEnv"- Родительское окружение (
enclosing environment) — окружение, в котором была объявлена функция. В большинстве случаев совпадает со связанным окружением, но не обязательно. Для пользовательских функций родительское окружение можно изменить, однако для функций, которые находятся в пакетах, неизменяемым родительским окружением будут пространства имён пакетов. Родительское окружение функции можно определить с помощьюenvironment().
# создаём под названием my_sd копию функции sd пакета stats
my_sd <- sd
find('my_sd')## [1] ".GlobalEnv"
# смотрим, в каком окружении определена функция sd, которую мы используем под названием my_sd
environment(my_sd)## <environment: namespace:stats>
# пример с новым пользовательским окружением
my_env <- new.env(parent = .GlobalEnv)
f_env <- function() print('function in my_env')
environment(f_env) <- my_env
find('f_env')## [1] ".GlobalEnv"
environment(f_env)## <environment: 0x56095292bc50>
f_env_global <- f_env
find('f_env_global')## [1] ".GlobalEnv"
environment(f_env_global)## <environment: 0x56095292bc50>- Локальное окружение (
local environment), оно же локальная область видимости функции: окружение, в котором выполняются выражения функции.
# создаём простую функцию с парой выражений
f_local <- function() {
x <- sample(10, 1)
y <- x * 5
# выводим на печать объекты из локальной области видимости функции
print(ls())
}
f_local()## [1] "x" "y"- Окружение вызова (
parent frame) — окружение, в котором вызывается функция. Окружение вызова можно определить или указать с помощью функцииparent.frame().
f_nested <- function() function() print(parent.frame())
f_nested()## function() print(parent.frame())
## <environment: 0x560951ca0650>Окружения пакетов и пространство имён
Код на R, как правило, организован модульно и состоит из пакетов, которые поставляются в базовом наборе от R Core Team, а также пользовательских пакетов и скриптов.
Каждый пакет — это несколько окружений, которые по определенной логике загружаются при подключении пакета. Окружения пакетов можно разделить на несколько видов:
package environment— окружение пакета, те функции и объекты, которые автор пакета сделал видимыми для пользователя. Обычно их описание можно найти в документации по пакету (если автор пакета её написал). Кроме этого список объектов, которые должны быть явно экспортированы, можно увидеть в файлеNAMESPACE. Просмотреть все объекты окруженияpackage environmentможно с помощью стандартной функцииls(), указав пакет, например,ls('package:readxl')(перед этим необходимо подключить пакет или его пространство имён,library('data.table')иattachNamespace('data.table')соответственно). Объекты пакета доступны в глобальном окружении либо после подключения пакета, либо с помощью оператора::, например,readxl::read_excel(), гдеreadxl— название пакета.package namespace— пространство имён пакета, все функции и объекты, которые входят в пакет. Это окружение отличается от предыдущего тем, что в нём есть объекты, скрытые от пользователя. Эти объекты необходимы для работы других (в том числе и видимых пользователю) функций, то есть это “технические” объекты. Например, функцииread_xls(),read_xlsx()иread_excel()пакетаreadxlиспользуют одну и ту же функцию внутреннююread_excel_(). Напрямую обратиться к этим объектам можно только через оператор:::, например,readxl:::read_excel_(). Получить полный список объектов из пространства имён пакета можно с помощью конструкции видаls(getNamespace('readxl), all.names = TRUE). Однако наилучший способ, по рекомендации Дирка Эдельбюттеля — посмотреть исходный код пакета, хотя это, конечно же, весьма трудоемкий процесс.package imports— те объекты, которые пакет импортирует и использует из других пакетов. Посмотреть, какие пакеты необходимы для работы, например, пакетаreadxl, можно таким образом:packageDescription('readxl')$Imports.
Стоит отметить, что окружение пакета и пространство имен пакета — это не два разных набора одних и тех же функций, а два разных набора указателей на одну и ту же функцию (или другой объект пакета). Это возможно в тех ситуациях, когда разные окружения используют одну и ту же функцию, и полезно при контроле, каким образом вызывается функция и к каким другим объектам она имеет доступ по правилам связывания.
Иерархия окружений
Окружения в R организованы в иерархию, и как правило имеют родителя. При старте сессии последовательно загружаются базовые окружения и окружения пакетов, тем самым образуя базовую иерархию окружений. Самым первым загружается пустое окружение (empty environment, R_EmptyEnv), далее — окружения пакета base и прочие. Всю цепочку загруженных окружений можно увидеть с помощью search(), однако информативнее иерархию окружений объекта строить с помощью функции parent.env() и её вызова в цикле (набор подключенных пакетов может отличаться в зависимости от сессии и настроек):
mf <- function(x)
repeat {
x_name <- environmentName(x)
cat(x_name, '\n')
if (identical(x, emptyenv()))
break
x <- parent.env(x)
}
mf(.GlobalEnv)## R_GlobalEnv
## package:stats
## package:graphics
## package:grDevices
## package:utils
## package:datasets
## package:methods
## Autoloads
## base
## R_EmptyEnvПоиск объектов в окружениях
Поиск объектов при вызове функций — наверное, одна из самых сложных вещей в конструкции R. В изолированных случаях проблем особых нет — в подавляющем большинстве используется лексическое связывание. То есть если в области видимости функции используется объект, который не был там создан и не является аргументом, то объект ищется в родительском окружении и далее по иерархии родительских окружений. Это простая схема усложняется, когда вызываются не пользовательские функции, а функции пакетов — пакеты мало того что могут подключаться в разном порядке, так ещё и некоторые из них имеют совпадающие по именам функции (например, lubridate::month() и data.table::month()). Дополнительные сложности возникают в ситуации, когда функция использует функцию другого пакета, который не был явно подключён пользователем.
Для того чтобы контролировать иерархию и взаимосвязи окружений, используется следующая логика. При подключении пакета последовательно подключаются окружение пакета, пространство имён пакета, окружение импортированных из других пакетов объектов. И самый важный момент — обновляется окружение environment: namespace:base.
Окружение namespace: base — то, где функция подключённого пакета считается как объявленная, то есть где функция ищет объекты, которые упоминаются в области видимости функции. Таким образом обеспечивается лексическое связывание для функций, которые объявляются в пакетах. В противном случае могла бы возникнуть путаница при одноименных функциях из разных пакетов.
Если попробовать посмотреть родительские окружения какой-нибудь из функций, например, sd(), доступных после старта сессии, то мы как раз увидим это усложнение иерархии окружений: помимо R_GlobalEnv до него будут ещё дополнительные окружения (в частности, environment: namespace:stats и environment: namespace:base):
Функция sd находится в пакете stats, выше по иерархии — пространство всех имён пакета stats и окружение импортированных объектов из других пакетов, ещё выше — namespace:base. При этом родительским окружением для namespace:base будет глобальное окружение. Таким образом, при вызове функции sd она обращается к функциям пакета stats (всего пространства имён), например, к функции var. А пространство имён environment: namespace:base — это окружение, в котором функция sd считается объявленной.
# повторяем функцию вывода родительских окружений
# только, помимо имён, выводим ещё и полные адреса окружения в памяти
mf <- function(x)
repeat {
attr(x, 'path') <- NULL
print(x)
if (identical(x, emptyenv()))
break
x <- parent.env(x)
}
mf(environment(sd))## <environment: namespace:stats>
## <environment: 0x56094e2b7828>
## attr(,"name")
## [1] "imports:stats"
## <environment: namespace:base>
## <environment: R_GlobalEnv>
## <environment: package:stats>
## attr(,"name")
## [1] "package:stats"
## <environment: package:graphics>
## attr(,"name")
## [1] "package:graphics"
## <environment: package:grDevices>
## attr(,"name")
## [1] "package:grDevices"
## <environment: package:utils>
## attr(,"name")
## [1] "package:utils"
## <environment: package:datasets>
## attr(,"name")
## [1] "package:datasets"
## <environment: package:methods>
## attr(,"name")
## [1] "package:methods"
## <environment: 0x56094ddc6ea8>
## attr(,"name")
## [1] "Autoloads"
## <environment: base>
## <environment: R_EmptyEnv>Нередко можно встретить рекомендации явно указывать используемые объекты в сочетании с пакетом, которому принадлежит эта функция: packagename::objectname. Это сделает код более надежным и, в какой-то мере, более читабельным. Однако при этом пострадает лаконичность кода, а также могут возникнуть сложности при совместном использовании кода разными людьми - используемый пакет должен быть установлен у пользователя. И если в обычной ситуации подключение пакета через library() в начале скрипта помогает понять, какие пакеты используются, то при использовании packagename::objectname лучше сделать дополнительный вступительный комментарий.
Non-standard evaluation
Non-standard evaluation можно перевести буквально как нестандартное выполнение выражений, однако аббревиатура NSE привычнее и чаще встречается даже в русскоязычных материалах, чем перевод. Поэтому далее будем использовать аббревиатуру NSE. NSE базируется на идущей от Lisp логики представления кода как данных, когда исполняемые выражения являются такими же объектами, как и, например, таблицы. Собственно, ключевая идея NSE заключается в разделении процессов создания выражения и выполнения этого выражения, что позволяет пользователю модифицировать выражение до того, как оно будет выполнено.
labelling
Хэдли Викхэм к виньетке по пакету lazyeval описывает три основные формы применения NSE. Первая из них, labelling (присваивание названия, аннотирование), встречается в некоторых базовых конструкциях R, например, в функции создания таблицы data.frame(). Несмотря на то, что data.frame — это, по сути список, присвоение названий колонкам в создаваемой таблице отличается от создания списка. Так, если не указывать названия колонок при названии датафрейма и при создании использовать уже существующие объекты, то имена этих объектов и будут присвоены в качестве названий колонок таблицы:
col1 <- 5
col2 <- 'abc'
my_df <- data.frame(col1, col2)
str(my_df)## 'data.frame': 1 obs. of 2 variables:
## $ col1: num 5
## $ col2: chr "abc"Точно так же названия и текстовые значения выражений при построении простейшего графика используются в качестве названий осей: название вектора с данными используется как название оси OX, а выражение, создающее значения по оси OY, — как название оси OY:
sin_values <- seq(0, 2 * pi, length = 100)
plot(sin_values, sin(sin_values), type = 'l', main = 'simple plot()')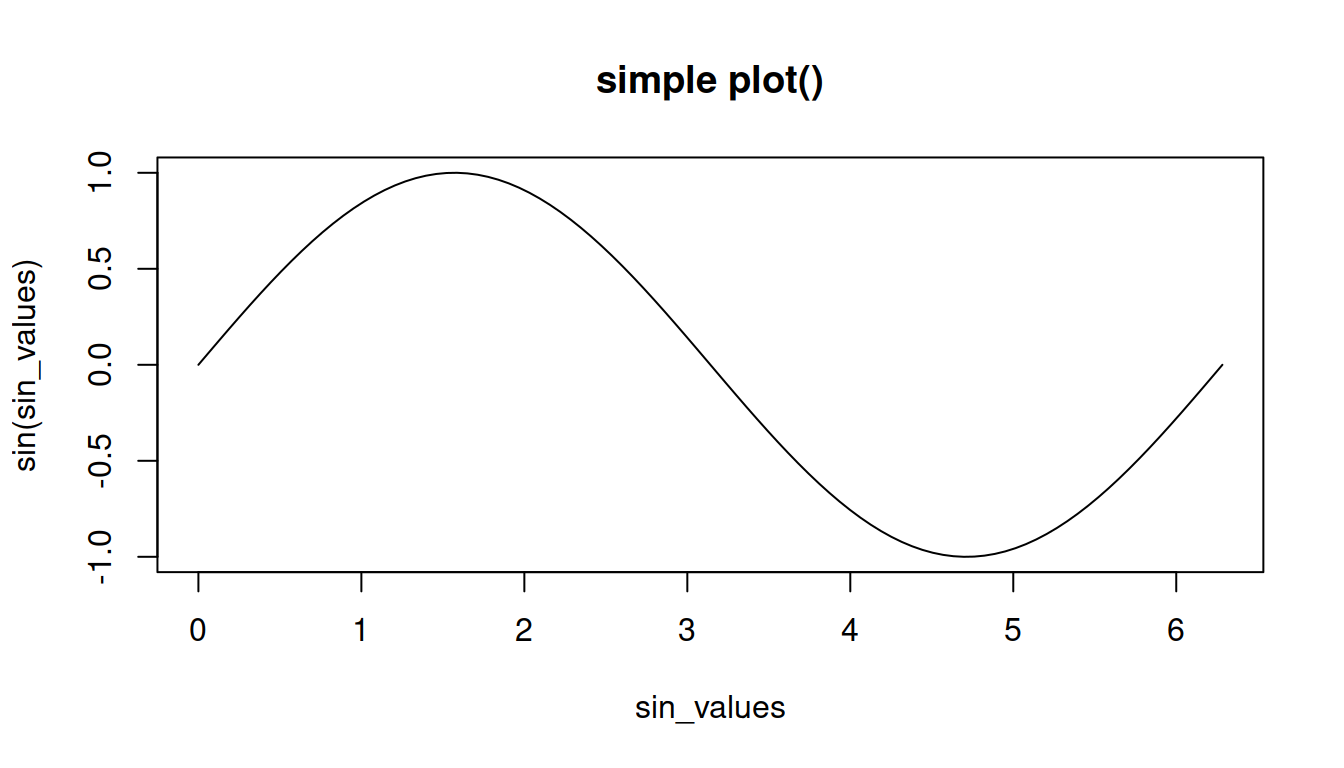
Если посмотреть, то в функции plot.default() для создания меток из названий использованных объектов есть соответствующие строчки, использующие комбинацию deparse() и substitute(). То есть сначала захватываются выражения, переданные в аргументы. Потом, так как объекты класса expression нельзя использовать для названий осей на графике, они преобразовываются в строки с помощью deparse(). В какой-то мере это поведение можно смоделировать в более короткой функции:
myplot <- function(x, y)
plot(x,
y,
xlab = deparse(substitute(x)),
ylab = deparse(substitute(y)),
type = "l",
main = 'deparse() + substitute()')
myplot(x = sin_values, y = sin(sin_values))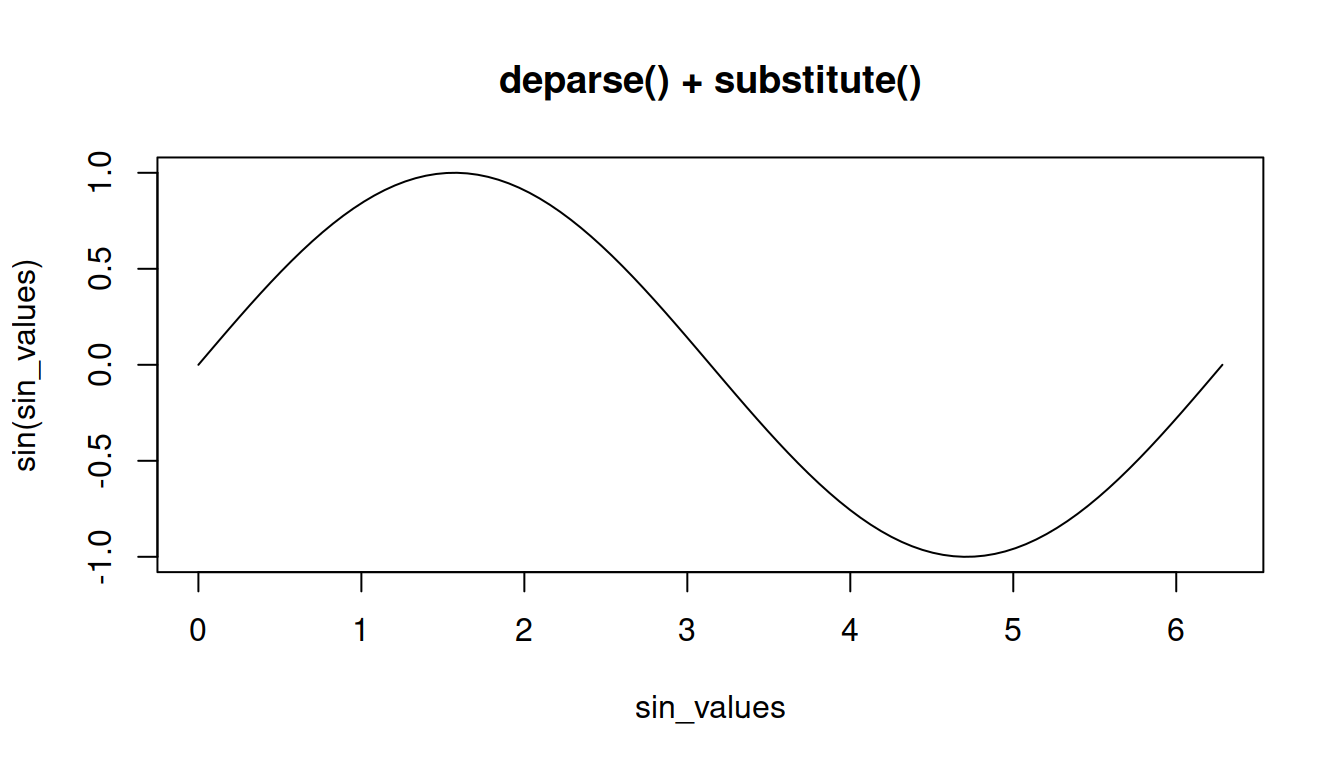
non standard scoping
Вторая форма NSE — это выполнение выражения в контексте объектов, а не окружений, на английском языке формулируется как non standard scoping. В каноничном примере из Advanced R это поведение демонстрируется на примере функции subset(). Сама функция subset() принадлежит базовому пакету и предназначена для выделения частей из векторов, матриц и таблиц. В функции subset.data.frame(), которая применяется к датафреймам, аргумент x используется для задания датафрейма, аргумент subset — для логического выражения, по которому будет фильтроваться указанный датасет:
args(subset.data.frame)## function (x, subset, select, drop = FALSE, ...)
## NULLТак работает функция subset.data.frame(): из таблицы df по условию на колонки выделяется таблица:
my_df <- data.frame(col1 = c(2, 5, 1, 3, 2),
col2 = c(5, 3, 1, 4, 1))В такой форме поиск объектов col1 и col2 происходит сначала в заданном объекте df, и только если там они не будут найдены, поиск обратится к родительскому окружению. Это и есть проявление NSE. Если посмотреть в код функции subset.data.frame, то можно увидеть такие строчки:
e <- substitute(subset)
r <- eval(e, x, parent.frame())Функция substitute() захватывает текст логического выражения, парсит, осуществляет необходимые подстановки и возвращает в виде выражения. Далее с помощью функции eval() выполняется полученное выражение в окружении x (указанный в аргументах датафрейм). parent.frame() в качестве значения аргумента enclos указывает, в каком лексическом контексте необходимо выполнять это выражение.
Смешанный пример, где в условии subset() используется сравнение значений колонки со значением отдельного объекта из глобального окружения. Значения z нет в таблице df, поэтому при выполнении выражения используется z из родительского (в данном случае глобального) окружения:
z <- 3
subset(my_df, col1 >= z)## col1 col2
## 2 5 3
## 4 3 4Такая организация работы функций с использованием NSE существенно экономит время на написание кода и в целом делает функции более простыми в использовании конечными пользователями, хотя и более сложными в отладке.
metaprogramming
Третья форма NSE — всё, что не может быть отнесено к первым двум вариантам, однако работает в аналогичном формате. По большей части это различные функции, которые относятся либо собственно к выполнению выражений (bquote()), либо к организации рабочего окружения (library(), help(), ls()) и прочим.
Самым наглядным примером тут будет функция library(). Как правило, у многих начинающих пользователей R возникает вопрос, почему функция library() может принимать название пакета как в кавычках (library('ggplot2')), так и без них (library(ggplot2)). Аргументы функции, которые помогают разобраться с этой ситуацией и увидеть, как в данном случае реализовано NSE, — package и character.only. Аргумент character.only по умолчанию имеет значение FALSE, то есть на месте package ожидается не строка, а объект.
args(library)## function (package, help, pos = 2, lib.loc = NULL, character.only = FALSE,
## logical.return = FALSE, warn.conflicts, quietly = FALSE,
## verbose = getOption("verbose"), mask.ok, exclude, include.only,
## attach.required = missing(include.only))
## NULLЕсли посмотреть код функции, то можно в середине функции (на примерно 169 строке из 388) увидеть блок, который отвечает за обработку аргументов package и character.only:
if (!missing(package)) {
if (is.null(lib.loc))
lib.loc <- .libPaths()
lib.loc <- lib.loc[dir.exists(lib.loc)]
if (!character.only)
package <- as.character(substitute(package))
if (length(package) != 1L)
stop("'package' must be of length 1")
if (is.na(package) || (package == ""))
stop("invalid package name")
}Нам интересна вот эта строчка, которая указывает, что если в аргумент package передана не строка (по умолчанию character.only == FALSE, а !FALSE == TRUE), то необходимо извлечь это выражение с помощью substitute() и превратить в строку.
if (!character.only)
package <- as.character(substitute(package))Таким образом, пользователь, когда хочет подключить какой-либо пакет, может указать просто его название без кавычек, и оно будет принято как выражение и преобразовано в строку, либо как объект, содержащий название пакета. При значении аргумента character.only == FALSE оба эти варианта будут идентичны.
Если поменять значение character.only на TRUE, то значение, переданное в package, будет выполнено, и именно результат выражения будет принят как название подключаемого пакета. Выражением же может быть как единичный строковый вектор (например, plotly), так и объект, содержащий название пакета. Это позволяет провернуть следующий трюк (который категорически не рекомендуется использовать в реальной разработке!), когда под названием одного пакета подключается совсем другой пакет:
## Error in detach("package:plotly", unload = TRUE): invalid 'name' argument## Error in detach("package:lme4", unload = TRUE): invalid 'name' argument
# создаём объект lme4 со значением plotly
lme4 <- 'plotly'
# проверяем, подгружены ли пакеты lme4 или plotly
c('lme4', 'plotly') %in% loadedNamespaces()## [1] FALSE FALSE
# подгружаем пакет через использование объекта с названием пакета
library(lme4, character.only = TRUE)
# проверяем, подгрузился ли пакет lme4
c('lme4', 'plotly') %in% loadedNamespaces()## [1] FALSE TRUEЦиклы
Наряду с условными операторами, циклы в R аналогичны циклам в других языках программирования. Три основных вида: for, while и repeat. Циклы задаются с помощью оператора цикла, последовательности или условия, ограничивающих работу цикла и, собственно, выполняемого выражения. Если это одна строка, то выражение можно не заключать в фигурные скобки, во всех прочих случаях фигурные скобки необходимы.
for, while и repeat имеют несколько важных особенностей. Во-первых, циклы не создают свою область видимости (локальное окружение), поэтому все операции, которые производятся над объектами в цикле, производятся в родительском окружении цикла и будут видны за его пределами. Во-вторых, в циклах в R происходит перебор элементов коллекции — то есть без объявления итератора, условий выхода или каких-то промежуточных действий.
Циклы традиционно редко используются в R, в немалой степени это вызвано спецификой использования памяти во время выполнения выражений в цикле. Если быть точнее, то не очень эффективным кодом циклов, который обычно пишут начинающие изучать язык. Для классических циклов существуют альтернативы — векторизованные вычисления и неявные циклы, а также, собственно, оптимизация кода путём преаллокации памяти или параллелизации.
Циклы for, while, repeat
for
Цикл for, который встречается чаще прочих, использует заданную последовательность, по которой и итерируется. Последовательностью может быть как числовой ряд, так и строковый вектор, например, вектор названий файлов при импорте и обработке большого количества файлов в одном цикле. После выполнения цикла используемый итератор имеет значение последнего элемента цикла. В том же случае, если последовательность нулевой длины, цикл не отрабатывает.
for (i in letters[1:3]) {
cat('letter', i, '\n')
}## letter a
## letter b
## letter c
cat('i =', i)## i = cwhile
Циклы while и repeat используются намного реже. Если в цикле for количество циклов определяется длиной заданной последовательности, то в while количество циклов может быть бесконечным до тех пор, пока поставленное условие будет верным.
Для цикла надо задать начальное значение счётчика циклов, задать условие для этого счётчика и не забыть дополнить тело цикла увеличением счётчика при каждой итерации. Либо же добавить любое другое изменение значения счётчика, которое может привести к срабатыванию условия. Второй вариант цикла while — это сначала создать объект с логическим значением TRUE и его поставить в условие, а потом прописать в теле цикла, что при определенных условиях значение сменится на FALSE, что и приведёт к остановке цикла.
Выведем первые три элемента вектора letters с помощью цикла while.
i <- 1
while (i < 4) {
my_l <- letters[i]
cat('letter', my_l, '\n')
i <- i + 1
}## letter a
## letter b
## letter c
cat('i =', i)## i = 4Как правило, while нужен тогда, когда надо подсчитать количество попыток до какого-то результата либо же неизвестно, сколько попыток может потребоваться. Самый показательный пример — сбор данных с POST-запросом, когда сервер может не отвечать, соединение может рваться, и так далее.
repeat
Цикл repeat схож с циклом while, только он выполняется до тех пор, пока при выполнении выражения не будет достигнут желаемый результат и не будет вызвана команда прерывания цикла. На том же примере с буквами:
i <- 1
repeat {
my_l <- letters[i]
if (i == 4) {
break()
} else {
cat('letter', my_l, '\n')
i <- i + 1
}
}## letter a
## letter b
## letter c
cat('i =', i)## i = 4Прерывание циклов
В какие-то моменты возникает необходимость прервать цикл или же пропустить последующие действия и начать новую итерацию цикла. Для этих целей используют функции break() и next() (в некоторых случаях еще continue и return). Выше в цикле repeat мы уже использовали break(), вот ещё один пример цикла с прерыванием:
for (i in letters[1:10]) {
cat(i, '\n')
if (i == 'c')
break()
}## a
## b
## cЭффективнее всего функции прерывания во вложенных циклах: если прервать выполнение вложенного цикла, то родительский цикл не будет прерван.
Неявные циклы, семейство *pply
Циклами в их привычном большинству программистов виде в R пользуются не очень часто. Как правило, это ситуации, когда неизвестно количество возможных циклов или, наоборот, их ничтожное количество (несколько названий файлов). В большинстве же случаев пользуются так называемыми неявными циклами — функциями семейства *pply.
Самая распространённая и покрывающая большинство задач функция семейства — это lapply(). Первый аргумент функции — набор элементов, над которыми должно быть произведено какое-то действие. Буква l в названии маркирует, что функция обычно применяется к спискам (l = list), однако на практике используются и векторы, и списки и т. д. Фактически первый аргумент в функции lapply() схож с итератором в цикле for. Второй аргумент — это собственно функция, которая должна быть применена к элементам вектора/списка из первого аргумента.
В качестве результата работы функция lapply() возвращает список, где каждый элемент — результат применения указанной во втором аргументе функции к каждому элементу первого аргумента. В этом заключается одно из отличий от классических циклов, в которых тело цикла всего лишь повторяется определённое количество раз. То есть в классических циклах, в отличие от lapply(), нет возможности создать объект с результатами цикла, и надо изменять созданный за пределами цикла объект.
## List of 5
## $ : num 1
## $ : num 1.41
## $ : num 1.73
## $ : num 2
## $ : num 2.24
unlist(res)## [1] 1.000000 1.414214 1.732051 2.000000 2.236068Если же у функции, используемой в lapply(), есть дополнительные аргументы, то они идут последующими аргументами, так как в списке аргументов lapply() заданы ..., дополнительные аргументы.
# создадим список из векторов
my_list <- list(el1 = c(1, 2, 3, 4),
el2 = c(1, 2, NA, 4))
# вычислим среднее и укажем, что NA надо пропускать
lapply(my_list, mean, na.rm = TRUE)## $el1
## [1] 2.5
##
## $el2
## [1] 2.333333Несмотря на определённую гибкость и возможность указывать аргументы функции, чаще всего в lapply() используются анонимные функции, в которые в качестве аргумента при выполнении передаётся значения объекта, переданного в первый аргумент (по которому осуществляется итерирование).
## List of 5
## $ : num 1.41
## $ : num 2
## $ : num 2.45
## $ : num 2.83
## $ : num 3.16
unlist(res)## [1] 1.414214 2.000000 2.449490 2.828427 3.162278Семейство *pply-функций достаточно велико, вот наиболее часто используемые функции (тут я ориентируюсь на список С. Мастицкого):
lapply():lв названии означаетlist, список. Используется в случаях, когда необходимо применить какую-либо функцию к каждому элементу списка и получить результат также в виде списка. На деле обычно служит более удобным аналогом циклаfor.sapply():sв названии означаетsimplify, упрощение. Работает какlapply(), только в результате отдаёт именованный вектор.apply(): используется в случаях, когда необходимо применить какую-либо функцию ко всем строкам или столбцам матрицы (или массивов большей размерности).vapply():vв названии означаетvelocity, скорость. Аналогичнаlapply()иsapply(), однако в качестве ещё одного аргумента требует указать тип данных, которые должны быть получены в результате. Это несколько ускоряет работу функции, что и привело к такому названию.mapply():mв названии означаетmultivariate, многомерный. Используется в случаях, когда необходимо поэлементно применить какую-либо функцию одновременно к нескольким объектам (например, получить сумму первых элементов векторов, затему сумму вторых элементов векторов и т. д.).rapply():rв названии означаетrecursively, рекурсивно. Используется в случаях, когда необходимо применить какую-либо функцию к компонентам вложенного списка.
Некоторые пакеты имеют свои реализации неявных циклов, например, parallel::mcmapply(), которая часто используется для параллелизации кода.
Векторизация
Векторизация — наверное, одна из самых примечательных и важных особенностей R как языка программирования и инструмента работы с данными. Фраза векторизованная функция означает, что операции производятся сразу над каждым элементом вектора. То есть там, где в других языках программирования (например, в Python) необходимо писать цикл или ламбда-функцию, в R можно просто передать вектор в аргументы функции. Нередко те, кто только начинает писать на R, не знают или забывают про векторизацию, что порождает странные и неоптимальные решения типа цикла по вектору или цикла по строкам датасета, чтобы изменить значения в колонке.
Например, функция round(), если в качестве аргумента использовать вектор значений, округлит до нужного знака каждый элемент вектора:
x <- rnorm(5, 0, 1)
x## [1] -1.35936855 -0.07411223 -1.32145136 -0.04982146 1.47400931
round(x, 3)## [1] -1.359 -0.074 -1.321 -0.050 1.474Выше, при описании lapply()), мы использовали как пример выражение lapply(1:5, sqrt). Это в определенной мере некорректное использование lapply(), так как функция sqrt() векторизована, как и большинство базовых функций в R.
Аналогично можно применять векторизованные операции к колонкам, чтобы изменить всю колонку сразу:
# создаём датасет
df <- data.frame(var1 = rnorm(5, 0, 1))
df## var1
## 1 1.3677436
## 2 -0.6381050
## 3 -1.8955751
## 4 0.4542755
## 5 2.4639582
# создаём колонку с округлёнными значениями
df$var1_round <- round(df$var1, 3)
df## var1 var1_round
## 1 1.3677436 1.368
## 2 -0.6381050 -0.638
## 3 -1.8955751 -1.896
## 4 0.4542755 0.454
## 5 2.4639582 2.464Большинство базовых операций в R векторизовано, то есть, применяется сразу к каждому элементу вектора. Это сильно упрощает вычисления и ощутимо повышает простоту и прозрачность кода. Точно так же векторизованной будет функция, если в её теле используются только векторизованные функции:
## [1] 1 8 96Тем не менее, надо учитывать, что все сложные пользовательские функции, как и ряд базовых функций, не векторизованы. В таких случаях можно попробовать векторизовать функцию с помощью Vectorize():
my_fun <- function(x, y) {
if (x <= y) {
-1
} else {
1
}
}
my_fun <- Vectorize(my_fun)
my_fun(1:6, 1:3)## [1] -1 -1 -1 1 1 1Функция Vectorize() воспринимает и поэлементно обрабатывает каждый вектор, переданный в аргументы функции. В некоторых случаях это приводит к некорректным ситуациям, и тогда надо явно указать, какой из аргументов необходимо векторизовать. Например, когда в функции производится нормировка элементов первого аргумента на агрегированный параметр второго вектора:
my_fun <- function(x, y) {
x - mean(y)
}
my_fun(1:5, 1:3)## [1] -1 0 1 2 3
# наивная векторизация
my_fun_vec <- Vectorize(my_fun)
my_fun_vec(1:5, 1:3)## Warning in mapply(FUN = function (x, y) : longer argument not a multiple of
## length of shorter## [1] 0 0 0 3 3
# векторизуем с указанием аргумента
my_fun_vec <- Vectorize(my_fun, vectorize.args = 'x')
my_fun_vec(1:5, 1:3)## [1] -1 0 1 2 3Это избыточный пример, так как my_fun() в данном случае использует векторизованную функцию вычитания и необходимости в векторизации нет. Впрочем, стоит отметить, что использование Vectorize() само по себе встречается редко и скорее используется либо профессиональными разработчиками, либо, наоборот, неопытными пользователями. Кроме того, если посмотреть на код функции Vectorize(), то видно, что эта функция является, по сути, сложной обёрткой над функцией mapply(), которую можно использовать и самостоятельно.
Условные операторы
if…else
Поведение условных операторов if и else в R аналогично другим языкам: если (if) условие верно, то выполняется первое выражение, если же неверно (else), то второе. Условие else является необязательным, также в коде вполне может встретиться несколько конструкций с if без последующего else.
Условие ветвления может быть задано как выражением, в результате которого возвращается единичное логическое TRUE/FALSE, так и объектом с логическим значением (результат проведённой отдельно проверки). Если в условие передан числовой объект, то он будет преобразован в логическое значение (0 — в FALSE, всё остальное — в TRUE). При комбинации нескольких логических проверок их объединяют через логические операторы && или ||.
Выражения, которые выполняются в if … else, желательно заключать в фигурные скобки, даже если это однострочное выражение (и обязательно, если это несколько выражений). Также следует помнить, что оператор else должен быть на той же строчке, на которой закрывается фигурная скобка оператора if. В противном случае эти два оператора будут проинтерпретированы как независимые и интерпретатор вернёт ошибку.
alarm <- 2 + 2 == 5
print(alarm)## [1] FALSE## Warning: Your math is broken!!!111ifelse
Конструкция if...else обладает одним ограничением: она не векторизована. То есть для того чтобы проверить, допустим, каждый элемент вектора, необходимо использовать циклы. Либо же обратиться к конструкции ifelse():
x <- 1:5
ifelse(x %% 2 == 0, 'even', 'odd')## [1] "odd" "even" "odd" "even" "odd"В примере мы создаём вектор от 1 до 5 и потом с помощью ifelse() проверяем каждый элемент на четность: если элемент делится на 2 без остатка, то возвращаем even, иначе же — odd. Как правило, ifelse() используется для модификации значений в колонках датасетов и любых других местах, когда надо не просто по условию выполнить какое-то выражение из пары альтернатив, а быстро модифицировать вектор значений.
switch
Функция switch() — очень удобный вариант ветвления в ситуациях нескольких альтернатив. Согласно документации, первым аргументом функции выступает строковое или числовое значение. Стоит учитывать, что в зависимости от типа (строка или число) несколько меняется поведение функции. Так, если первым аргументом передаётся числовое значение, то функция возвращает альтернативу под таким номером из указанного вторым и следующими аргументами списка альтернатив. Если значение первого аргумента превышает количество альтернатив, то функция ничего не вернёт (точнее, вернет NULL):
switch(3,
"Amber",
"Westeros",
"Westworld",
"Cadia")## [1] "Westworld"## NULLЕсли в функцию передается строковое значение (и это наиболее частое применение), то второй и следующие аргументы — это также список альтернатив, но альтернатив именованных. Это необходимо, так как строковое значение не может быть использовано как номер альтернативы в списке. Список альтернатив должен быть именован в соответствии с допустимыми (или желаемыми) вариантами значений первого аргумента. Также можно указать одну альтернативу без имени, которая будет возвращаться по умолчанию (когда в первом аргументе будет значение, не совпадающее с названиями именованных альтернатив). Функция switch() чаще всего используется при создании функций. В примере ниже функция poles_of_existence возвращает вектор имён ключевых элементов вселенной “Хроник Амбера” Роджера Желязны.
# объявляем функцию
poles_of_existence <- function(pole) {
switch(
pole,
Chaos = c('Serpent', 'The Logrus', 'Suhuy', 'Courts of Chaos'),
Order = c('Unicorn', 'The Pattern', 'Dworkin Barimen', 'Amber'),
'unknown'
)
}
# вызываем имена и объекты Хаоса
poles_of_existence('Chaos')## [1] "Serpent" "The Logrus" "Suhuy" "Courts of Chaos"
# пробуем другой аргумент, которого нет в списке имён альтернатив
poles_of_existence('Westeros')## [1] "unknown"Иногда в функцию передается элемент сортированного вектора с уровнями (фактора). В таком случае происходит преобразование типа значения в character и функция работает как со строковым значением, несмотря на уровни фактора. Одновременно пользователю при интерактивной работе возвращается предупреждение. Впрочем, это достаточно редкий и вырожденный случай, которого следует избегать.