Ввод и вывод данных
Чтение ввода пользователя
При интерактивной работе в консоли R временами возникает необходимость прочитать вводимые пользователем значения. В какой-то мере это одна из классических учебных и иллюстративных задач, так как в реальной практике такие задачи встречаются только при реализации интерактивного взаимодействия с пользователем (например, обучающий пакет swirl).
Чтение ввода пользователя осуществляется с помощью функции readline() (ниже скопирована последовательность ввода в консоли):
> user_input <- readline()
a b_c
> print(user_input)
[1] "a b_c"Второй, более редкий вариант интерактивного ввода данных пользователем — функция menu(), в которой можно дать пользователю возможность выбрать вариант из списка. При использовании аргумента graphics = TRUE поднимается интерактивное окно. Простейший пример использования menu() (также скопирована копия последовательности ввода в консоли):
> menu(choices = c("List letters", "List LETTERS"))
1: List letters
2: List LETTERS
Selection: 1
[1] 1Вывод сообщений
Вывод на печать
print()
Для вывода на печать обычно используют функцию print() и в некоторых случаях cat(). Функция print(), пожалуй, одна из самых часто используемых функций, даже простейшую отладку делают с её помощью. print() — это функция-дженерик, для очень большого числа классов определяется свой метод print(). Например, методы для линейных моделей и обобщенных линейных моделей:
## [1] "print.glm" "print.lm" "print.summary.glm"
## [4] "print.summary.lm"Так как print() для каждого класса может иметь свои параметры, рассмотрим функцию print.default(), которая применяется для вывода на печать векторов. Как правило, для print() не используют дополнительные аргументы, в большом количестве случаев вообще даже саму функцию не пишут — и IDE, и консоль R интерпретируют вызов объекта в консоли как вывод на печать:
x <- 1:5
print(x)## [1] 1 2 3 4 5
x## [1] 1 2 3 4 5Основные аргументы — quote и digits. При quote = TRUE во время вывода строки скрываются окружающие кавычки:
print('This is a string')## [1] "This is a string"
print('This is a string', quote = FALSE)## [1] This is a stringАргумент digits менее очевиден: с его помощью задаётся количество значимых знаков, которое должно быть отображено (а не количество знаков после запятой, как в одноимённом аргументе функции round()). При этом по умолчанию считается, что значимых знаков семь. Также стоит учитывать, что если целая часть больше 22 знаков, то результат будет представлен в академическом (scientific) формате в виде числа с плавающей точкой (если не выставлено options(scipen = 999)):
# двузначное число с дробной частью, всего пять знаков
x <- 85.547
print(x)## [1] 85.547
print(x, digits = 3)## [1] 85.5
# число длиной в девять знаков
x <- 198789.547
print(x)## [1] 198789.5
print(x, digits = 10)## [1] 198789.547
# число длиной 30 знаков
x <- 38955015567677251979744654351
print(x)## [1] 3.895502e+28Такая логика характерна не только для базового print(), но и для некоторых других функций и классов (например, View() или некоторые функции в tidyverse). Вызвано это стремлением упростить пользователю жизнь и не перегружать лишней информацией: предполагается, что если дробная часть числа существенно меньше целой, то её наличие или отсутствие мало повлияет на решение пользователя, при этом всё число восприниматься будет проще. Важно понимать, что результат print() — это именно отображение данных пользователю, а не реальное округление, и используется только для числовых векторов:
x <- 38901556.7677251
print(x)## [1] 38901557
print(as.character(x))## [1] "38901556.7677251"Другой нюанс функции print(): она не только выводит на печать значение, но и возвращает его. То есть с точки зрения кода вполне легальна ситуация из примера ниже. Правда, уже с точки зрения читабельности и адекватности подобные решения лучше не использовать. Особенно в тех ситуациях, когда print() используется в функции для промежуточного контроля.
## [1] 5 2 3 1 4
print(x)## [1] 5 2 3 1 4cat()
Функция cat() во многом повторяет функционал print.default(), в том числе и подход к отображению длинных чисел. Однако cat() намного удобнее использовать в ситуации, когда необходимо из нескольких переменных собрать одну текстовую строку и её вывести на печать (так как cat идет от concatenate). Это заменяет связку функций paste() + print().
## 5 random numbers = 5 2 3 1 4Так как cat() склеивает переданные объекты, то и вывод в консоли идет на одной строке, в том числе на этой строке оказывается и следующее выражение. Для переноса строки необходимо указать разделитель sep = '\n':
# без разделителя
cat(1:3)## 1 2 3
x <- 'new object'
# с разделителем
cat(1:3, sep = '\n')## 1
## 2
## 3
x <- 'new object'Информационные сообщения: message, warning, stop
В функциях нередко используют информационные сообщения — message(), warning() и stop(). Первая функция используется, когда необходимо что-то сообщить об операциях во время выполнения функции. Например, если в функции необходимо сделать дополнительную конвертацию строкового значения в числовое:
# объявляем функцию, которая умножает значение на 5
my_fun <- function(x) {
if (is.character(x)) {
x <- as.numeric(x)
message('Converted char x into numeric')
}
x * 5
}
# передаем в x строковое значение
my_fun('3')## Converted char x into numeric## [1] 15Функция warning() используется в том случае, если есть какая-то особенность при выполнении функции, которая может влиять на результат. Например, при умножении двух векторов разных размеров происходит повторное использование элементов более короткого вектора до достижения равной длины. В целом использование функции вызывает ряд вопросов, так как допускает ситуацию, когда пользователь может проигнорировать предупреждение и получить некорректный результат. К тому же в большинстве случаев ситуации, классифицируемые как требующие внимания, стоит называть ошибками.
## Warning in c(1, 2, 3, 4, 5) * c(3, 2): longer object length is not a multiple of
## shorter object length## [1] 3 4 9 8 15stop() используется в схожих случаях, как и warning(), однако не дожидается окончания выполнения функции, а завершает выполнение и извещает пользователя об ошибке. Например:
# объявляем функцию, которая умножает значение на 5
my_fun <- function(x, y) {
if (length(x) != length(y))
stop('Alarm! length(x) != length(y)')
x * y
}
# передаём в x строковое значение
my_fun(x = 1:5, y = 3:2)В целом в качестве функций информационных сообщений можно использовать и print() / cat(). Однако эти группы функций различаются тем, что вывод print() / cat() направляется в поток стандартного вывода (stdout), а вывод информационных функций — в поток ошибок (stderr). Использование потока stderr выделяет визуально эти сообщения, а также их вывод может использоваться в tryCatch() (подробнее см. про обработку ошибок). Ещё один нюанс, который стоит иногда принимать во внимание — некоторые авторы используют suppressMessages(), suppressWarnings(), которые скрывают вывод message() и warnings().
Чтение и запись текстовых файлов
В работе аналитики и исследователи чаще всего сталкиваются с данными, которые хранятся в простом текстовом формате (txt, разделители строк \n, \r или \n\r ) и основанных на них табличных форматах csv (с разделителями , или ;) или tsv (\t).
Построчное чтение
При работе с текстами проще всего читать файлы построчно: весь текст импортируется как вектор строковых значений, а элементы этого вектора — блоки текста, ограниченные переносами строк. Это удобно при импорте текстов, в которых есть смысловые блоки, как в художественных и поэтических текстах. Точно так же построчное чтение может быть использовано для импорта файлов с ошибками или даже, в особо экзотических случаях, для чтения скриптов.
Для построчного чтения обычно используется функция readLines() базового пакета или аналогичные ей. С помощью аргументов функции можно указать, сколько необходимо прочитать строк, задать кодировку и что делать, если в файле меньше строк, чем было задано.
Прочитаем первые несколько строк текста песни:
txt_lines <- readLines('./data/oxxy_gorgorod.txt', n = 5)
txt_lines## [1] "####"
## [2] "Незаметно поправь её"
## [3] "Одеяло, за это себя предавая анафеме"
## [4] "Она вышла из пены"
## [5] "Худой отпечаток плеча оставляя на кафеле"Чтение текстовых файлов: read.table()
Для чтения текстовых файлов, которые содержат в табличном формате, в базовом R есть функция read.table() и функции-обертки, которые обращаются к ней, но с другими значениями аргументов по умолчанию (read.csv(), read.csv2, read.delim(), read.delim2()). Табличный формат предполагает наличие строк и колонок в файле, выделенных разделителями строк и полей соответственно, при этом формат файла может быть как txt, так и csv.
Несмотря на всю видимую простоту, при импорте табличных форматов можно столкнуться с очень большим количеством нетривиальных проблем. В немалой части это можно назвать следствием их широкой распространенности: практически все современные текстовые процессоры умеют работать с csv-файлами, экспорт из баз данных также нередко делается в csv. Ко всему прочему, текстовые форматы хорошо сжимаются при архивации.
К наиболее частым сложностям, которые возникают при импорте текстовых файлов, можно отнести следующие:
- неожиданные разделители (например, экспорт из MS Excel в
csvсоздаёт файл с разделителем;); - лишние или пропущенные разделители строк или колонок (
\t\tвместо\t), что создаёт разное количество колонок в таблице; - несоответствие файла расширению или вообще отсутствие расширения;
- нестандартные кодировки, в том числе проблемы их импорта при работе в Windows;
- наличие embedded nuls (
\0) или метки порядка байтов (bite order marks, BOM); - наличие символов
"""",////и прочих технических символов - метаданные (запись о дате и источнике данных) в первых строках файла.
Большинство этих нюансов решается при настройке параметров импорта с помощью аргументов функций импорта (т. е. настройки по умолчанию не справляются). В частности, в функциях чтения таблиц можно задать разделители полей и десятичные разделители (sep и dec), кодировку файла и отображения, обработку пустых строк и т. д. Некоторые проблемы, например, импорт данных с embedded nuls, постепенно решаются в новых версиях функций и пакетов. Помимо этих аргументов, также очень полезны аргументы, которые позволяют прямо указать, сколько строк импортировать (или пропустить от начала), какие типы данных в колонках и какие колонки стоит пропустить, а также надо ли конвертировать в факторы строковые значения.
Рассмотрим сложный пример, когда в txt-файле находятся табличные данные, при этом кодировка файла отличается от распространенных (UTF-16), в дополнение к этому в качестве десятичного разделителя используется ,. Вот так выглядит файл при печати в терминале:
cat ./data/txt_example.txt## ��▒>4>4@ ▒>4>< 08<5=>20=85 @>872>48B5;L #?0: 5AOF
## 69500044 008560521 &▒ . 10 ! <1% - 2AB@8O 4 5
## 69500044 745621 &▒ . 10 ! <1% - 2AB@8O 4 5
## 69500300 69506432458 ▒! " 100 N20 (@5O 9D !05=A87 2B. 4 1 5
## 69500346 695089466518 &▒ ▒▒ " 25 N50 ▒!▒ =65@>-!C465=A:89 %$, 3 5
## 69500268 69504851543 $▒"! ! #!▒▒"+ !2 $/ 2 N20 ▒ ! !▒ ▒ ! !▒▒! - 1 5
## 69500009 69506584554 ▒ !. ▒. /!▒'-▒ !"&+ ! ',▒ % ▒-#, @.6 "#! - -" 1 5
## 69500058 86600383 ".. N10 $ !" " $ !" " 10 5
## 69500147 41200521 &▒ . 10 ! <1% - 2AB@8O 4 5
## 69500147 05860521 &▒ . 10 ! <1% - 2AB@8O 4 5
## 69500268 00000927 ▒"".. 20 N28 545>= 8EB5@ 2 5При желании можно распознать заголовки и разделители колонок (табуляция). Тем не менее, файл в таком виде не годится для работы. После некоторого перебора типов кодировок выяснилось, что файл представлен в кодировке UTF-16. Зададим все аргументы для корректного импорта:
path <- './data/txt_example.txt'
txt_data <- read.table(path, header = TRUE, fileEncoding = 'UTF-16', sep = '\t', dec = ',')Посмотрим на файл и структуру данных. Как мы видим, весь файл импортирован как таблица. А до версии R 4.0.0 текстовые данные были бы ещё и преобразованы в факторы, так как в ранних версиях аргумент stringsAsFactors по умолчанию имел значение TRUE:
head(txt_data, n = 3)## КодПодр КодНом Наименование Производитель Упак
## 1 69500044 ЛН-008560521 БАНЕОЦИН ПОР. 10Г САНДОЗ ГмбХ - Австрия 4
## 2 69500044 ЛН-745621 БАНЕОЦИН ПОР. 10Г САНДОЗ ГмбХ - Австрия 4
## 3 69500300 69506432458 НИМЕСАН ТАБЛ. 100МГ N20 Шрея Лайф Саенсиз Пвт. Лтд 1
## Месяц
## 1 5
## 2 5
## 3 5
str(txt_data)## 'data.frame': 10 obs. of 6 variables:
## $ КодПодр : int 69500044 69500044 69500300 69500346 69500268 69500009 69500058 69500147 69500147 69500268
## $ КодНом : chr "ЛН-008560521" "ЛН-745621" "69506432458" "695089466518" ...
## $ Наименование : chr "БАНЕОЦИН ПОР. 10Г" "БАНЕОЦИН ПОР. 10Г" "НИМЕСАН ТАБЛ. 100МГ N20" "ЦИННАРИЗИН ТАБЛ. 25МГ N50 АВЕКСИМА" ...
## $ Производитель: chr "САНДОЗ ГмбХ - Австрия" "САНДОЗ ГмбХ - Австрия" "Шрея Лайф Саенсиз Пвт. Лтд" "Анжеро-Судженский ХФЗ,ООО" ...
## $ Упак : int 4 4 1 3 1 1 10 4 4 2
## $ Месяц : int 5 5 5 5 5 5 5 5 5 5К наиболее трудным проблемам до недавнего времени можно было отнести наличие embedded nuls в тексте, так как это требовало предобработки в bash. Сейчас некоторые функции импорта (например, data.table::fread()) умеют обрабатывать такие ситуации.
Другая проблема — наличие сдвоенных разделителей полей (например, \t\t) в файлах с большим количеством пропусков. В таких файлах нельзя заменить сдвоенный разделитель на одинарный, так как неизвестно, чем является этот разделитель: ошибкой файла или же эти два разделителя ограничивают пустую ячейку, которая будет заполнена NA при импорте. К сожалению, эта проблема вряд ли может быть решена простым путем.
Из других не очень очевидных нюансов стоит отметить, что функция read.table() удобна, так как обладает большим набором аргументов, а также устойчива к некоторым ошибкам в данных. Однако импорт данных с её помощью весьма нетороплив, что ощутимо сказывается при импорте больших таблиц. Поэтому лучше использовать аналогичные функции других пакетов, в частности, data.table::fread().
Запись данных в текстовые файлы: cat, writeLines, write.table
Записывать данные в текстовые форматы можно как построчно, так и сразу всей таблицей. Для записи построчно обычно используется функция writeLines(), в редких случаях — cat() (при указании имени файла происходит перенаправление вывода с консоли в файл).
Запишем построчно прочитанные ранее строки и посмотрим в терминале, что получилось:
writeLines(txt_lines, con = './data/lines.txt')cat ./data/lines.txt## ####
## Незаметно поправь её
## Одеяло, за это себя предавая анафеме
## Она вышла из пены
## Худой отпечаток плеча оставляя на кафелеЗапись таблиц происходит аналогичным образом с помощью функции write.table() или её аналогом в других пакетах (в частности, более быстрый вариант — data.table::fwrite()). С помощью аргументов можно задать как типы разделителей (строк, полей и десятичные разделители), так и кодировку.
Ранее в таблицах использовались осмысленные названия строк, поэтому функции для записи по умолчанию сохраняли в файл отдельной колонкой и названия строк. Сейчас именование строк встречается реже, поэтому можно выставлять аргумент row.names = FALSE, чтобы в файл не были записаны отдельной колонкой бесполезные номера строк.
write.table(txt_data, './data/txt_example2.txt', row.names = FALSE)Смотрим результат. Как мы видим, в отличие от первоначального формата, таблица уже в более читабельной кодировке:
cat ./data/txt_example2.txt## "КодПодр" "КодНом" "Наименование" "Производитель" "Упак" "Месяц"
## 69500044 "ЛН-008560521" "БАНЕОЦИН ПОР. 10Г" "САНДОЗ ГмбХ - Австрия" 4 5
## 69500044 "ЛН-745621" "БАНЕОЦИН ПОР. 10Г" "САНДОЗ ГмбХ - Австрия" 4 5
## 69500300 "69506432458" "НИМЕСАН ТАБЛ. 100МГ N20" "Шрея Лайф Саенсиз Пвт. Лтд" 1 5
## 69500346 "695089466518" "ЦИННАРИЗИН ТАБЛ. 25МГ N50 АВЕКСИМА" "Анжеро-Судженский ХФЗ,ООО" 3 5
## 69500268 "69504851543" "ФИТОСЕДАН СБОР УСПОКОИТЕЛЬНЫЙ №2 Ф/П 2Г N20 КРАСНОГОРСК" "КРАСНОГОРСКЛЕКСР-ВА" 1 5
## 69500009 "69506584554" "БАНДАЖ КОМПРЕС. ПОДДЕРЖИВ. ПОЯСНИЧНО-КРЕСТЦОВЫЙ С ОВЕЧЬИМ МЕХОМ БКД-УНГА, р.6" "ТОНУС - ЭЛАСТ" 1 5
## 69500058 "ЛН-86600383" "АЛЛОХОЛ ТАБЛ.П.О. N10 ФАРМСТАНДАРТ" "ФАРМСТАНДАРТ" 10 5
## 69500147 "ЛН-41200521" "БАНЕОЦИН ПОР. 10Г" "САНДОЗ ГмбХ - Австрия" 4 5
## 69500147 "ЛН-05860521" "БАНЕОЦИН ПОР. 10Г" "САНДОЗ ГмбХ - Австрия" 4 5
## 69500268 "ЛН-00000927" "КВАМАТЕЛ ТАБЛ.П.О. 20МГ N28" "Гедеон Рихтер" 2 5Чтение и запись файлов MS Excel
В отличие от простых форматов типа csv, файлы, созданные в MS Excel, импортировать не так просто. Ситуация ещё осложняется и тем, что форматы xls и xlsx сильно различаются по внутренней структуре. Часть пакетов, которые обеспечивают взаимодействие с Excel-файлами, требуют установки языка и компилятора Java (java development kit, jdk) в систему и соответствующих R-пакетов (rJava, в частности) — самые часто используемые пакеты тут XLconnect и xlsx. Тем не менее, в большинстве случаев необходимо только прочитать файл, и тут могут быть полезны пакеты openxlsx и readxl, не требующие установки jdk. Пакет openxlsx к тому же умеет ещё и записывать файлы в .xlsx, как XLconnect, в том числе и с условным форматированием ячеек.
Чтение файлов
Пакет readxl, по наблюдениям, чуть быстрее читает файлы, чем openxlsx или пакеты, требующие Java, поэтому рассмотрим здесь его. В целом функционал пакетов достаточно схож, и то, что может readxl, практически всегда можно реализовать и в других пакетах, и наоборот.
Основные функции пакета: read_xls() для чтения файлов MS Excel, созданных в версиях до MS Excel 2007, read_xlsx() для чтения файлов, созданных в более современных версиях, также есть обобщающая функция read_excel(), которая по расширению файла определяет, какую из этих функций надо использовать. Пакет readxl принадлежит к экосистеме tideverse, поэтому импортированные таблицы имеют класс tibble и data.frame. Соответственно, если предполагается дальше работать с ними в data.table, то необходимо их отдельно явно преобразовать.
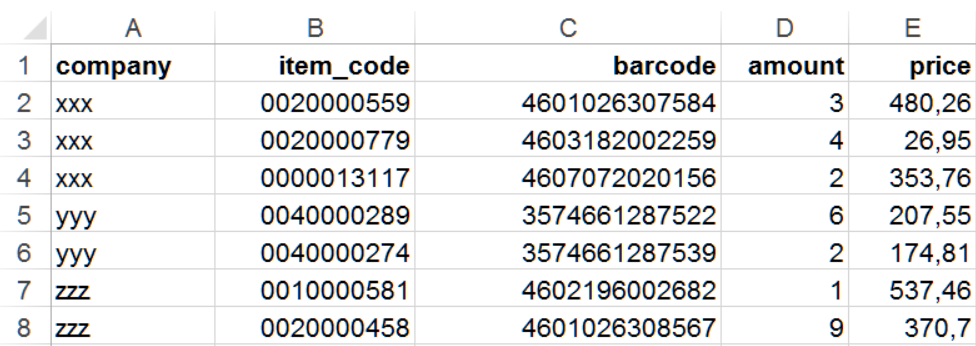
Импортируем файл:
library(readxl)
# читаем файл
path <- './data/xls_example.xlsx'
xlsx_data <- read_xlsx(path)
str(xlsx_data)## tibble [7 × 5] (S3: tbl_df/tbl/data.frame)
## $ company : chr [1:7] "xxx" "xxx" "xxx" "yyy" ...
## $ item_code: num [1:7] 20000559 20000779 13117 40000289 40000274 ...
## $ barcode : num [1:7] 4.60e+12 4.60e+12 4.61e+12 3.57e+12 3.57e+12 ...
## $ amount : num [1:7] 3 4 2 6 2 1 9
## $ price : num [1:7] 480.3 26.9 353.8 207.6 174.8 ...
xlsx_data## # A tibble: 7 × 5
## company item_code barcode amount price
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 xxx 20000559 4601026307584 3 480.
## 2 xxx 20000779 4603182002259 4 27.0
## 3 xxx 13117 4607072020156 2 354.
## 4 yyy 40000289 3574661287522 6 208.
## 5 yyy 40000274 3574661287539 2 175.
## 6 zzz 10000581 4602196002682 1 537.
## 7 zzz 20000458 4601026308567 9 371.При импорте можно указать тип колонок. Делается это с помощью аргумента col_types, в который необходимо передать вектор такой же длины, сколько колонок, состоящий из значений logical, numeric, date, text или list. К сожалению, в отличие от схожего аргумента colClasses в функциях импорта csv/xlsx-файлов (read.table(), read.csv(), data.table::fread(), openxlsx::read.xlsx и проч.), в readxl названия типов не соответствуют названиям атомарных типов данных в R.
Если для col_types указать NULL или guess, то тип будет выбран на основе анализа минимум 1000 строк (или всех строк, если датасет меньше 1000 строк). Также можно указать вектор типов длиной не по количеству колонок, а только из одного значения, тогда все колонки будут импортированы в этом типе. Значение skip указывает, что эту колонку не надо импортировать.
# читаем файл с указанием типа text для всех колонок
xlsx_data <- read_xlsx(path, col_types = 'text')
xlsx_data## # A tibble: 7 × 5
## company item_code barcode amount price
## <chr> <chr> <chr> <chr> <chr>
## 1 xxx 20000559 4601026307584 3 480.26
## 2 xxx 20000779 4603182002259 4 26.95
## 3 xxx 13117 4607072020156 2 353.76
## 4 yyy 40000289 3574661287522 6 207.55
## 5 yyy 40000274 3574661287539 2 174.81
## 6 zzz 10000581 4602196002682 1 537.46
## 7 zzz 20000458 4601026308567 9 370.7Как мы видим, readxl обладает рядом особенностей: во-первых, в колонке price, если её импортировать как числовую, показаны только целые значения, это сделано сознательно, так как дробные части существенно меньше целых (подробнее см. раздел про print()). Но это именно формат отображения таблички, а не реальное округление при импорте. А во-вторых, что важнее, в колонке item_code все значения в исходном файле начинаются с двух или трёх нулей. И на данный момент, несмотря на то, что эта проблема известна, readxl не умеет импортировать строковые значения, которые начинаются с одного или нескольких нулей. Например, 0020000559 импортируется как 20000559 даже при col_types = 'text'. Вообще, как оказалось, только функции пакета XLconnect способны импортировать данные в таком виде корректно, прочие часто используемые пакеты (readxl, openxlsx, xlsx) ошибаются.
В очень редких случаях случается так, что файл имеет формат xlsx, а расширение — xls. В таком случае функции импорта readxl выдадут ошибку, так как они при чтении файла делают проверку на его расширение. Тут может помочь проверка первых символов каждого файла (у xlsx-файлов первые четыре символа — это PK\003\004) и последующая смена расширения файла:
readChar(path, nchars = 4L, useBytes = TRUE)## [1] "PK\003\004"Частичное чтение файла
Большинство xlsx-файлов содержит несколько непустых листов. По умолчанию функции импорта читают только первый лист, остальные же игнорируются. Пакеты типа XLConnect могут читать весь файл в отдельный объект. Для чтения названий листов xlsx-файла можно воспользоваться функцией readxl::excel_sheets(), и полученный вектор потом циклом или через lapply() передать в функцию импорта:
# читаем список листов файла
sheets <- readxl::excel_sheets(path)
sheets## [1] "Sheet1" "Sheet2"
# читаем все листы в список и смотрим структуру
file_str <- lapply(sheets, function(x) read_xlsx(path, sheet = x))
str(file_str)## List of 2
## $ : tibble [7 × 5] (S3: tbl_df/tbl/data.frame)
## ..$ company : chr [1:7] "xxx" "xxx" "xxx" "yyy" ...
## ..$ item_code: num [1:7] 20000559 20000779 13117 40000289 40000274 ...
## ..$ barcode : num [1:7] 4.60e+12 4.60e+12 4.61e+12 3.57e+12 3.57e+12 ...
## ..$ amount : num [1:7] 3 4 2 6 2 1 9
## ..$ price : num [1:7] 480.3 26.9 353.8 207.6 174.8 ...
## $ : tibble [3 × 2] (S3: tbl_df/tbl/data.frame)
## ..$ company: chr [1:3] "xxx" "yyy" "zzz"
## ..$ items : num [1:3] 198 256 32В некоторых случаях требуется импортировать только определённый диапазон ячеек со всего листа: например, когда на созданном вручную листе есть и таблица с данными, и графики, и дополнительные материалы. Для чтения определённой ячейки или диапазона ячеек используют аргумент range, в котором в строковом виде указывают диапазон ячеек в Excel-координатах (буквы для колонок и цифры для строк). К сожалению, на данный момент нельзя указать сразу несколько диапазонов. Во-вторых, в прочитанном диапазоне, если не указать обратное, первая строка будет по умолчанию интерпретироваться как строка заголовка. В результате приходится либо прямо задавать названия колонок, либо указывать, что заголовка нет:
## # A tibble: 2 × 2
## company item_code
## <chr> <dbl>
## 1 yyy 40000289
## 2 yyy 40000274Сохранение Excel-файлов
С помощью пакета readxl нельзя сохранять файлы, для этого приходится обращаться к пакетам writexl, openxlsx или XLconnect. openxlsx, на мой взгляд, предпочтительнее, так как не требует установки Java, а так же имеет возможность сохранения Excel-файлов с условным форматированием таблиц.
При импорте файла с помощью пакета openxlsx можно импортировать все листы сразу, в один объект класса Workbook.
library(openxlsx)
xlsx_data <- loadWorkbook(path)
class(xlsx_data)## [1] "Workbook"
## attr(,"package")
## [1] "openxlsx"Функция conditionalFormatting задает правила, условия и стили условного форматирования ячеек в файле. В отличие от большинства других функций в R, она реализована так, что изменение происходит через изменение объекта на месте, нет необходимости перезаписывать импортированный Workbook. В аргументах функции указывается область, к которой должно быть применено условное форматирование (sheet, cols, rows), а также правила и цветовые схемы (type и style).
# задаём правило условного форматирования - градиент от 'lightskyblue2' до 'steelblue3' по значениям в колонке 'price' на первом листе.
conditionalFormatting(xlsx_data, sheet = 1, cols = 5, rows = 2:8, type = 'colorScale', style = c('lightskyblue2', 'steelblue3'))Помимо условного форматирования, в Excel-файл также можно добавлять свои таблицы и записывать их на отдельные листы и даже на отдельные ячейки в уже существующих листах. Добавим первые шесть строк таблицы iris на первый лист ниже уже существующей таблицы. После применения правил условного форматирования и добавления таблицы на лист сохраняем модифицированный объект в файл.
# добавляем таблицу на 10 и следующие строки первого листа
writeDataTable(xlsx_data, sheet = 1, x = head(iris), startRow = 10, tableStyle = 'none', withFilter = FALSE)
# сохраняем
saveWorkbook(xlsx_data, file = './data/xls_example2.xlsx', overwrite = TRUE)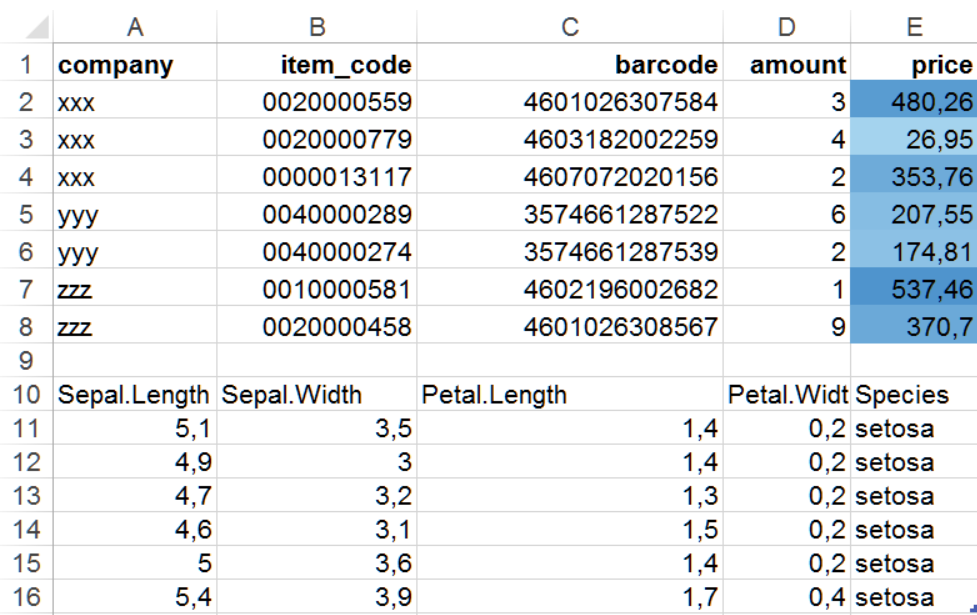
Чтение и запись файлов SPSS
В России в академической среде очень распространён SPSS, пакет для анализа данных в социальных науках. Особенно активно им пользуются психологи и социологи, для которых это до сих пор практически стандарт для хранения данных, а также инструмент первого выбора при анализе. Впрочем, ряд ограничений (высокая стоимость, ограниченный набор методов, своеобразный синтаксис) приводит к тому, что исследователи постепенно переходят на R и/или Python.
Чтение файлов SPSS
Для импорта файлов SPSS (.sav) обычно используют функции какого-либо из двух пакетов: foreign::read.spss(), который идет в базовом наборе пакетов R, а также haven::read_spss() авторства Хэдли Викхэма.
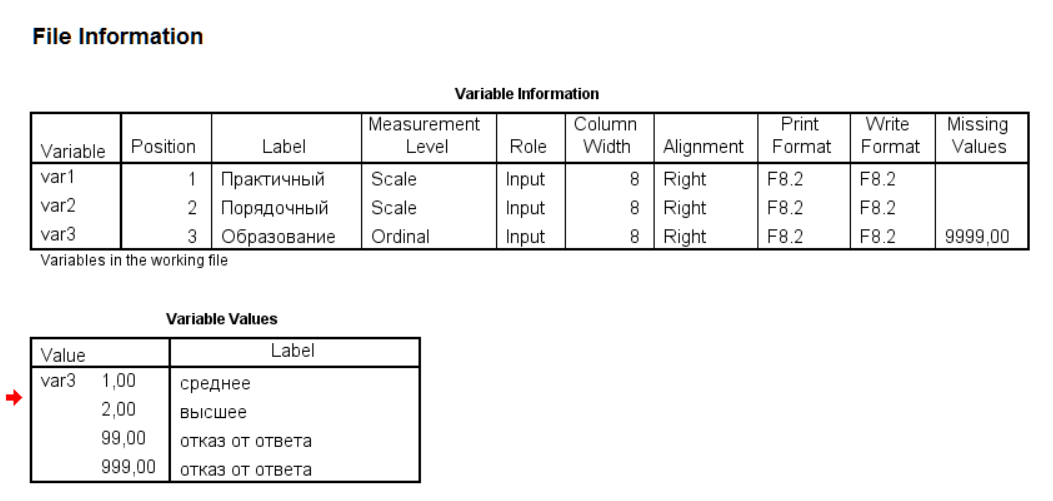
foreign::read.spss()
Читаем файл сразу с указанием необходимости перекодировки в кодировку локали (аргумент reencode) и выводим на печать.
library(foreign)
path <- './data/spss_example.sav'
spss_data <- read.spss(file = path, reencode = TRUE)## re-encoding from UTF-8## Warning in read.spss(file = path, reencode = TRUE): Undeclared level(s) 4, 9999
## added in variable: var3## Warning in read.spss(file = path, reencode = TRUE): Duplicated levels in factor
## var3: отказ от ответаПервое, на что надо обратить внимание, — то, что в колонке var3 есть значение 4, для которого нет заданной метки. Вторая важная деталь — для метки отказ от ответа есть два разных числовых кода, что также указывается в предупреждении.
В результате такого импорта мы получаем список с достаточно сложной структурой и большим количеством атрибутов. Если посмотреть на содержание, то видно, что для var3 метки значений импортированы как факторы. При этом вторая метка 999 = отказ от ответа импортирована по правилу paste0(label, duplicated.value.labels.infix, level), где duplicated.value.labels.infix = '_duplicated_' по умолчанию. В атрибутах хранятся именованные векторы для меток значений и метки переменных (label.table и variable.labels), а также тип указания пропущенных значений (одно, несколько, диапазон) и сама метка пропущенного значения (missings).
spss_data## $var1
## [1] 3 4 3 3 4 3
##
## $var2
## [1] 4 5 5 5 4 5
##
## $var3
## [1] среднее 9999
## [3] отказ от ответа среднее
## [5] 4 отказ от ответа_duplicated_999
## 6 Levels: среднее высшее 4 отказ от ответа ... 9999
##
## attr(,"label.table")
## attr(,"label.table")$var1
## NULL
##
## attr(,"label.table")$var2
## NULL
##
## attr(,"label.table")$var3
## отказ от ответа отказ от ответа высшее среднее
## "999" "99" "2" "1"
##
## attr(,"variable.labels")
## var1 var2 var3
## "Практичный" "Порядочный" "Образование"
## attr(,"missings")
## attr(,"missings")$var1
## attr(,"missings")$var1$type
## [1] "none"
##
##
## attr(,"missings")$var2
## attr(,"missings")$var2$type
## [1] "none"
##
##
## attr(,"missings")$var3
## attr(,"missings")$var3$type
## [1] "one"
##
## attr(,"missings")$var3$value
## [1] 9999
##
##
## attr(,"codepage")
## [1] 65001Для того чтобы прочитать файл в привычный табличный вид и учесть выданные предупреждения, необходимо воспользоваться рядом дополнительных аргументов. Во-первых, аргумент to.data.frame = TRUE позволяет нам получить данные в виде data.frame без каких-либо дополнительных конверсий, к тому же при импорте будут применены правила для указания пользовательских пропусков (9999 для NA-значений, как и задано в файле). Второй полезный аргумент use.value.labels = FALSE указывает, что в результате импорта должны быть не метки значений, а сами значения. Таким образом, данные из колонки var3 будут импортированы как числа, соответственно, метка отказ от ответа для значений 99 и 999 не будет вызывать конфликта при формировании уровней фактора.
spss_data <- read.spss(
file = path,
to.data.frame = TRUE,
use.value.labels = FALSE,
reencode = TRUE
)## re-encoding from UTF-8
spss_data## var1 var2 var3
## 1 3 4 1
## 2 4 5 NA
## 3 3 5 99
## 4 3 5 1
## 5 4 4 4
## 6 3 5 999Несмотря на то, что импорт данных в табличном виде удобен, таким образом теряется ощутимое количество информации. Тем не менее, наиболее часто используемые метки переменных все же сохранены:
attributes(spss_data)## $names
## [1] "var1" "var2" "var3"
##
## $class
## [1] "data.frame"
##
## $row.names
## [1] 1 2 3 4 5 6
##
## $variable.labels
## var1 var2 var3
## "Практичный" "Порядочный" "Образование"
##
## $codepage
## [1] 65001haven::read_sav()
Функции read_sav() и read_spss() пакета haven обладают схожим функционалом при меньшем количестве настроек. При этом они несколько быстрее foreign::read.spss(), а также не имеют проблем с длинными строками. В результате импорта получается tibble-таблица (так как haven принадлежит экосистеме tidyverse).
## # A tibble: 6 × 3
## var1 var2 var3
## <dbl> <dbl> <dbl+lbl>
## 1 3 4 1 [среднее]
## 2 4 5 NA
## 3 3 5 99 [отказ от ответа]
## 4 3 5 1 [среднее]
## 5 4 4 4
## 6 3 5 999 [отказ от ответа]Функция не имеет настроек, как импортировать значения, для которых заданы метки, и в таблице представлены числовые значения. При необходимости получить метки переменных или значений необходимо идти в атрибуты колонок таблицы:
str(spss_data)## tibble [6 × 3] (S3: tbl_df/tbl/data.frame)
## $ var1: num [1:6] 3 4 3 3 4 3
## ..- attr(*, "label")= chr "Практичный"
## ..- attr(*, "format.spss")= chr "F8.2"
## $ var2: num [1:6] 4 5 5 5 4 5
## ..- attr(*, "label")= chr "Порядочный"
## ..- attr(*, "format.spss")= chr "F8.2"
## $ var3: dbl+lbl [1:6] 1, NA, 99, 1, 4, 999
## ..@ label : chr "Образование"
## ..@ format.spss: chr "F8.2"
## ..@ labels : Named num [1:4] 1 2 99 999
## .. ..- attr(*, "names")= chr [1:4] "среднее" "высшее" "отказ от ответа" "отказ от ответа"Нередко возникает необходимость иметь не только значения, но и их метки, например, для var3 (уровень образования) из примера. В таких случаях помогает функция haven::as_factor():
as_factor(spss_data$var3)## [1] среднее <NA> отказ от ответа среднее
## [5] 4 отказ от ответа
## attr(,"label")
## [1] Образование
## Levels: среднее высшее 4 отказ от ответаЗапись файлов SPSS
Для сохранения данных в SPSS-формате используется функция write_sav() пакета haven. Помимо собственно значений, можно указать текстовую метку создаваемой переменной, а также формат хранения (количество знаков для целой и десятичной частей числа). Создадим две переменных, числовую и строковую:
# создаём числовую переменную
spss_data$var4 <- sample(nrow(spss_data))
attr(spss_data$var4, 'label') <- 'новая чисовая переменная'
attr(spss_data$var4, 'format.spss') <- 'F8.2'
# создаём строковую переменную
spss_data$var5 <- month.abb[1:nrow(spss_data)]
attr(spss_data$var5, 'label') <- 'новая строковая переменная'
attr(spss_data$var5, 'format.spss') <- 'A8'Для создания переменной, в которой используются метки значений (в том числе и пользовательские метки для пропущенных значений), необходимо использовать функцию labelled_spss(). Создадим переменную из нулей и единиц с метками Нет и Да соответственно. Также укажем, что 9999 используется для обозначения пропущенных значений (за это отвечают аргументы na_values и na_range).
# создаём вектор
spss_data$var6 <- sample(c(0, 1), nrow(spss_data), replace = TRUE)
# задаём формат числа
attr(spss_data$var6, 'format.spss') <- 'F1.0'
# задаём метки с помощью именованного вектора в labels
spss_data$var6 <- labelled_spss(
spss_data$var6,
na_values = 9999,
labels = c('Нет' = 0, 'Да' = 1),
label = 'новая переменная с метками'
)Из-за того, что при импорте колонки var3 пользовательская метка пропуска была заменена на NA, надо её тоже указать, заодно зададим новую метку для значения 4:
# корректируем метки значений в var3
var3_labels <- c(attr(spss_data$var3, 'labels'), 'новая метка' = 4)
var3_labels <- sort(var3_labels)
spss_data$var3 <- labelled_spss(
spss_data$var3,
na_values = 9999,
labels = var3_labels,
label = 'Образование'
)
# сохраняем всё в файл
write_sav(spss_data, './data/spss_example2.sav')Структура обновленного файла:
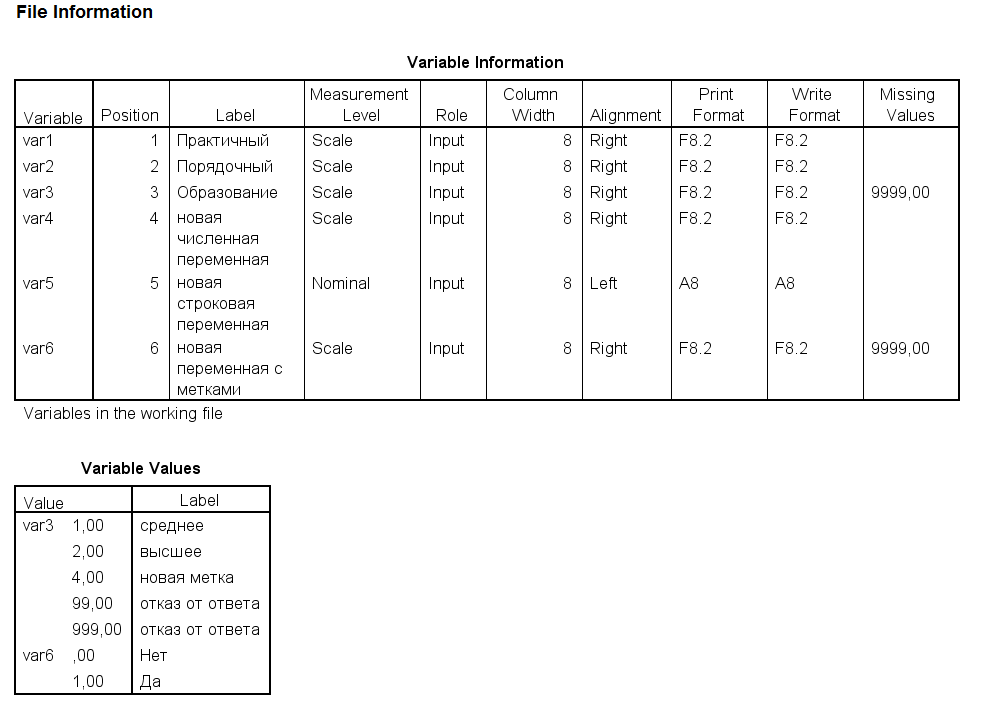
Чтение и запись JSON
json-файлы можно парсить как простые файлы со строками, однако эффективнее использовать пакет jsonlite, в котором присутствуют функции как чтения, так и записи объектов в json-виде.
Для чтения обычно используют функцию fromJSON(), а в некоторых редких случаях — stream_in(), которая на вход принимает файлы, соединения или ссылки на файл в njson-формате. Вот так выглядит json-файл примера (для простоты чтения здесь он представлен в pretty-формате, в реальности это, конечно же, должна быть одна строка):
cat ./data/json_example.json## [{
## "name":"Thor",
## "parents": {
## "father":"Odin",
## "mother":"Jord"
## },
## "weapon": "Mjölnir"
## },
## {
## "name":"Loki",
## "parents": {
## "father":"Farbauti",
## "mother":"Laufey"
## }
## }]Функция fromJSON() по умолчанию старается привести результат к табличному виду. В большинстве случаев это, к сожалению, невозможно. В частности, когда присутствует несколько вложенных массивов разной длины. Ключ для вложенного массива используется как префикс в названии колонки, полученной из массива:
## name parents.father parents.mother weapon
## 1 Thor Odin Jord Mjölnir
## 2 Loki Farbauti Laufey <NA>Запись объектов в json-формате осуществляется с помощью toJSON() или с помощью stream_out(). При этом надо учитывать, что при прямой записи с помощью toJSON() требуется указать значения большого количества аргументов, поэтому можно прибегнуть к простому трюку: сначала создать из таблицы json-объект с помощью toJSON(), а результат записать в файл построчно функцией writeLines():
json_parsed$spouse <- c('Sif', 'Sigyn')
writeLines(toJSON(json_parsed), con = './data/json_example2.json')Смотрим результат, он должен быть одной строкой:
cat ./data/json_example2.json## [{"name":"Thor","parents":{"father":"Odin","mother":"Jord"},"weapon":"Mjölnir","spouse":"Sif"},{"name":"Loki","parents":{"father":"Farbauti","mother":"Laufey"},"spouse":"Sigyn"}]Чтение и запись XML/HTML
Для парсинга данных в XML формате обычно используют один из двух пакетов, XML и xml2, — они в целом схожи по функционалу, несмотря на то, что xml2 появился чуть ли не на 15 лет позже и во многом вдохновлен пакетом XML. Оба пакета регулярно обновляются и в целом взаимозаменяемы. Здесь я рассматриваю xml2, в немалой степени из-за того, что в пакете xml2 для навигации по нодам дерева разметки и для извлечения элементов и атрибутов используется язык XPath (в XML обращаться к нодам можно через оператор [[). Так как языки разметки XML и HTML схожи по организации, то логика парсинга xml-данных может быть легко перенесена на html-разметку и, соответственно, скрапинг web-страниц. Собственно, пакет rvest, который используется для скрапинга (авторства Хэдли Викхема, как и xml2) является оберткой над xml2.
Рассмотрим сложный кейс — xml-файл, в котором есть вложенные массивы и пропущенные значения. Вот так выглядит импортируемый файл:
cat ./data/xml_example.xml## <?xml version="1.0" encoding="UTF-8"?>
## <edda>
## <character>
## <name>Thor</name>
## <parents>
## <father>
## <name>Odin</name>
## <weapon>Gungnir</weapon>
## </father>
## <mother>
## <name>Jord</name>
## </mother>
## </parents>
## <weapon>Mjölnir</weapon>
## </character>
## <character>
## <name>Loki</name>
## <parents>
## <father>
## <name>Farbauti</name>
## </father>
## <mother>
## <name>Laufey</name>
## </mother>
## </parents>
## </character>
## </edda>Для обхода нод и выделения необходимых элементов можно воспользоваться функцией xml_find_all(), однако у неё есть большой минус: в случае пропусков в данных пропущенные значения будут заполнены последними не-NA значениями. Поэтому для того, чтобы учесть наличие вложенных элементов и пропусков, необходимо перебирать одинаковые по структуре блоки данных и указывать необходимые элементы с помощью XPath-путей. Для того чтобы в пути указать номер блока, я использовал функцию glue::glue(), более удобный аналог paste().
При таком процессе обработки функция xml_find_first() отдаёт первую встреченную ноду по указанному пути, при этом её дополнительно надо преобразовать в текст с помощью функции xml_text(). Для числовых значений, если бы они были, пришлось бы использовать xml_double() или xml_integer().
# подключаем библиотеку и импортируем файл
library(xml2)
library(glue)
path <- './data/xml_example.xml'
xml_data <- read_xml(path)
# считаем количество блоков по персонажам "Эдды"
n_chars <- xml_length(xml_data)
# итерируемся по блокам, номер блока указываем в XPath-пути
xml_data_parsed <- lapply(seq_len(n_chars), function(x) {
data.frame(
character = xml_text(xml_find_first(xml_data, glue('//character[{x}]/name'))),
father = xml_text(xml_find_first(xml_data, glue('//character[{x}]/*/father/name'))),
father_weapon = xml_text(xml_find_first(xml_data, glue('//character[{x}]/*/father/weapon'))),
mother = xml_text(xml_find_first(xml_data, glue('//character[{x}]/*/mother/name'))),
weapon = xml_text(xml_find_first(xml_data, glue('//character[{x}]/weapon')))
)
})
# собираем список таблиц в одну общую таблицу
xml_data_parsed <- do.call(rbind, xml_data_parsed)
xml_data_parsed## character father father_weapon mother weapon
## 1 Thor Odin Gungnir Jord Mjölnir
## 2 Loki Farbauti <NA> Laufey <NA>Для сравнения, какой получается результат при прямолинейном использовании xml_find_all() или XML::xmlToDataFrame(): в первом случае некорректно обрабатываются пропуски, во втором — значения вложенных элементов оказываются слиты в одну строку и также не очень корректно обрабатываются пропуски:
# при использовании xml_find_all() вместо обхода по блокам и xml_find_first()
data.frame(
character = xml_text(xml_find_all(xml_data, '//character/name')),
father = xml_text(xml_find_all(xml_data, '//character/parents/father/name')),
father_weapon = xml_text(xml_find_all(xml_data, '//character/parents/father/weapon')),
mother = xml_text(xml_find_all(xml_data, '//character/parents/mother/name')),
weapon = xml_text(xml_find_all(xml_data, '//character/weapon'))
)## character father father_weapon mother weapon
## 1 Thor Odin Gungnir Jord Mjölnir
## 2 Loki Farbauti Gungnir Laufey Mjölnir
# при использовании xmlToDataFrame() пакета xml
XML::xmlToDataFrame(XML::xmlParse(path))## name parents weapon
## 1 Thor OdinGungnirJord Mjölnir
## 2 Loki FarbautiLaufey <NA>Запись и чтение R-объектов: RData, RDS
В том случае, когда необходимо сохранить на диск какой-нибудь R-объект, например, регрессионную модель, проще всего воспользоваться одним из нативных форматов, .Rds или .RData (.Rda). Оба формата создаются через обращение к функции сериализации serialize().
Для сохранения в формат .Rds нужна функция saveRDS(). Этот формат используется для сохранения единичных R-объектов, притом можно указать алгоритм сжатия (по умолчанию gzip, а также bzip2, xz):
# создаём объект и смотрим его размер в байтах
x <- rnorm(1e6)
object.size(x)## 8000048 bytes
# сохраняем в rds
saveRDS(x, file = './data/rds_example.rds')Смотрим размер результата в терминале:
wc -c ./data/rds_example.rds## 7678250 ./data/rds_example.rdsДля сохранения нескольких объектов можно использовать функцию save() и сохранять объекты в файл с расширением .RData или .Rda. При сохранении данные также будут архивированы с помощью выбранного алгоритма. Функция save.image() — аналог функции save(), в которой в список объектов передан список объектов глобального окружения с их именами (ls(all.names = TRUE)). Основное отличие .RData от .Rds: с помощью первого можно сохранить несколько объектов, а с помощью .Rds — только один.
Создадим и проверим, что у нас в рабочем окружении два объекта. Сохраним:
## [1] "x" "y"Импорт данных из форматов .Rds и .RData осуществляется двумя функциями — readRDS() и load() соответственно. Тем не менее, есть одно существенное различие: функция readRDS() по использованию похожа на все остальные функции импорта, т. е. результат её выполнения может быть записан как новый объект (связан с новым именем). Загрузка данных из .RData с помощью load() фактически восстанавливает сохранённые объекты в рабочем окружении (либо в специально указанном окружении). И если результат load() записывать в новый объект, то в этом объекте будут только названия объектов, сохранённых в .RData:
# очистим окружение для наглядности
rm(list = ls())
# прочитаем данные из .RData и .RDS
load('./data/rda_example.RData')
rda_data <- load('./data/rda_example.RData')
rds_data <- readRDS('./data/rds_example.rds')
# смотрим объекты окружения и их классы
ls()## [1] "rda_data" "rds_data" "x" "y"## rda_data rds_data x y
## "character" "numeric" "character" "numeric"
# отдельно смотрим структуру объекта rda_data
str(rda_data)## chr [1:2] "x" "y"